
Dans ce billet, j’aimerais vous présenter les différentes briques techniques permettant de mettre en œuvre une architecture microservices reposant sur Spring Boot, Spring Cloud, Netflix OSS et Docker. Pour m’y aider, je m’appuierai sur l’application démo Spring Petclinic Microservices que je vous avais déjà brièvement présenté en 2016 et que j’ai récemment migrée vers Spring Cloud Finchley et Spring Boot 2.
Ce fork a été construit à partir de l’application monolithique spring-petclinic-angularjs. Cette dernière a été découpée en plusieurs services, chacun responsable d’un domaine métier de la clinique vétérinaire : les animaux et leurs propriétaires, leurs visites à la clinique et les vétérinaires.
Au final, Spring Petclinic Microservices est construit autour de petits services indépendants (quelques centaines de ligne de code), s’exécutant dans leur propre JVM et communiquant sur HTTP via une API REST.
Ces microservices sont tous écrits en Java. Mais on aurait pu utiliser Kotlin pour développer certains d’entre eux. Le front est quant à lui codé en JavaScript.
Architecture technique
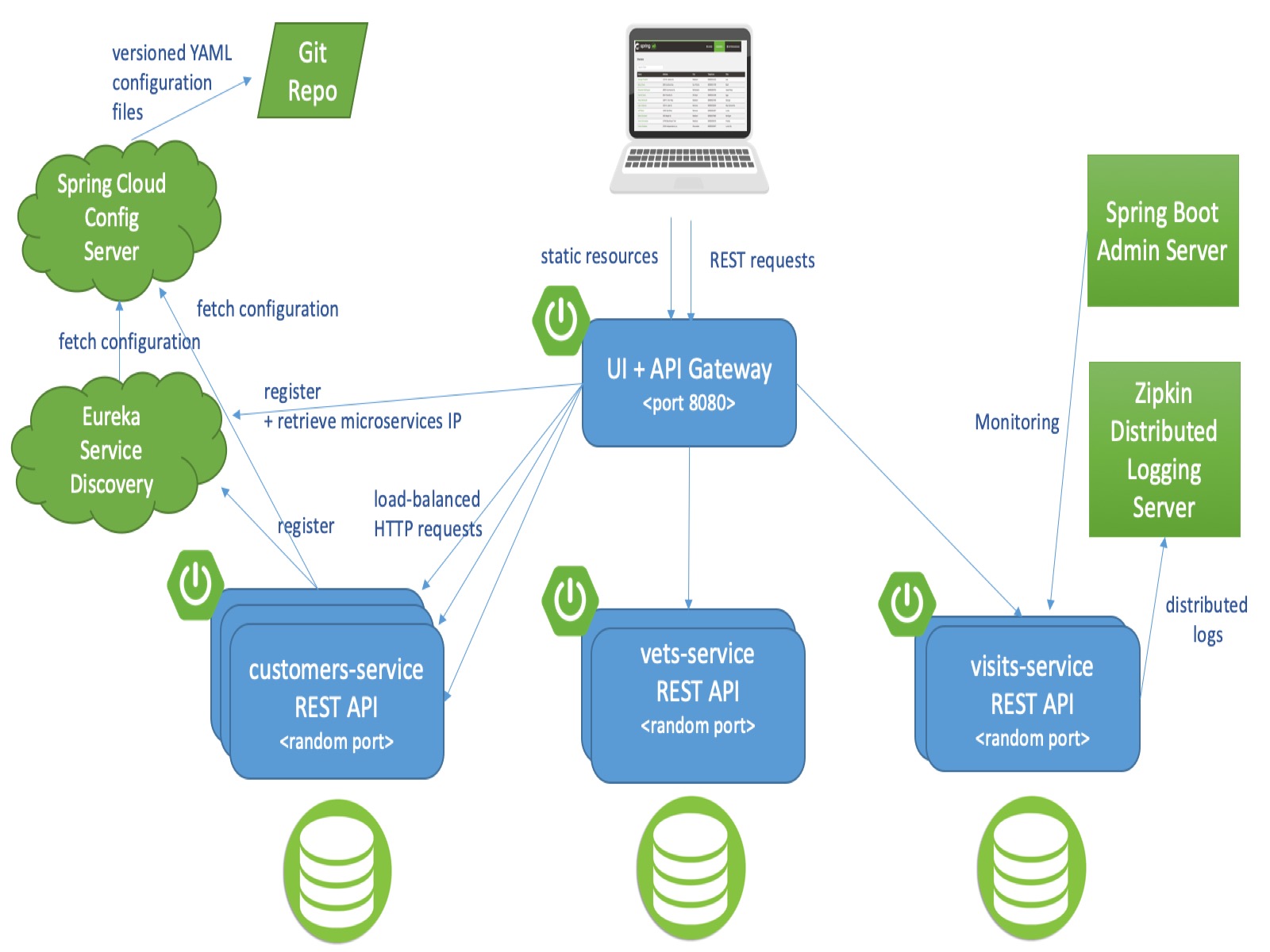
Pour fonctionner, les différents microservices composant l’application Petclinic reposent sur différentes briques techniques matérialisées sur le diagramme d’architecture ci-dessous :

Remarque : pour simplifier le diagramme, les flèches partant de customers-service et visits-service peuvent être transposées aux « xxx-services » homologues.
Vue d’ensemble des briques techniques :
- En bleu, les 3 microservices back exposent le fonctionnel de l’application au travers d’une API REST. Pour assurer la scalabilité horizontale et la tolérance aux pannes, plusieurs instances d’un même microservice peuvent être démarrées simultanément. Afin d’être autonome, chaque microservice dispose de sa propre base de donnée. Cependant, toutes les instances d’un même microservice partagent la même base de données (qui pourrait être clusterisé). Le front-end JavaScript n’attaque pas directement ces 3 microservices : il passe par le microservice front API Gateway qui s’occupe également de desservir les ressources statiques (code JavaScript, pages HTML et CSS).
- En vert, on retrouve les microservices d’infrastructures :
- L’annuaire de service Eureka va permettre aux microservices de s’enregistrer puis de communiquer sans connaître par avance leurs adresses IP.
- Les microservices (ainsi que les autres serveurs) vont charger leur configuration applicative depuis le Serveur de Config. Les fichiers de configuration sont versionnés sur le dépôt de code GitHub spring-petclinic-microservices-config.
- Optionnel, les traces des différents appels peuvent être remontées dans le serveur de logs distribués Zipkin.
Enfin, pour superviser et administrer les différents microservices, les Ops peuvent compter sur le serveur Spring Boot Admin.
Spring Boot taillé pour les Microservices
Bien que ne faisant pas partie des microframeworks Java, Spring Boot se prête parfaitement au développement de Microservices par ses nombreux atouts :
- Génération d’un microservice packagé sous forme d’un JAR. Ce JAR inclue le serveur web (conteneur de Servlets ou Netty). Le microservice ne nécessite qu’une simple JVM pour s’exécuter.
- Diminution de la base de code par un allègement important de la configuration des différents frameworks (dans Petclinic : Spring MVC, Spring Data JPA, EhCache). Spring Boot détecte les frameworks présents dans le classpath et les configure automatiquement. Des starters additionnels viennent étendre cette fonctionnalité.
- Monitoring et gestion des microservices en Production au travers d’endpoint REST exposés à l’aide des Actuator.
Chacun des 4 microservices métiers customers, vets, visits et api-gateway est une application au sens Spring Boot. Chacun dispose de son propre module Maven contenant quelques classes Java et fichiers de configuration.
Par exemple, le module spring-petclinic-visits-service comporte 4 classes :
- VisitsServiceApplication: la classe main du microservice annotée avec l’annotation @SpringBootApplication ainsi que l’annotation Spring Cloud @EnableDiscoveryClient dont nous verrons l’intérêt par la suite.
- Visit : entité JPA représentant une visite et référençant l’animal par son ID (et non son type Java) dans un soucis de découplage des microservices.
- VisitRepository: interface Spring Data JPA implémentant le pattern Repository et permettant d’accéder aux visites stockées dans une base relationnelle (HSQLDB ou MySQL).
- VisitResource : contrôleur REST exposant une API pour créer une visite et lister les visites d’un animal. L’usage d’annotations Lombok permet d’alléger le code, mais n’a rien d’obligatoire.
Comme vous le constatez, mise à part l’annotation Spring Cloud @EnableDiscoveryClient, le code Java de ce microservice ressemble à une application REST Spring Boot des plus classique.
Une différence significative se trouve au niveau de leur configuration Maven (pom.xml) et de leur configuration applicative (.yml).
Intégration de Spring Cloud
Pour fonctionner de concert dans un environnement distribué, ces microservices vont s’appuyer sur un ensemble d’outils proposés par Spring Cloud : une gestion centralisée da la configuration, la découverte automatisée des autres microservices, la répartition de charge et le routage d’API.
Intégrer ces différentes fonctionnalités Spring Cloud dans une application Spring Boot commence par la déclaration de starters Spring Cloud au niveau du pom.xml. Pour utiliser ces starters sans se soucier de leur version, un prérequis consiste à importer le BOM spring-cloud-dependencies (ex : le pom parent de Spring Petclinic Microservices) :
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencyManagement>
Dans tous les différents microservices de Petclinic, on a commencé par ajouter le starter spring-cloud-starter-config qui permet d’aller récupérer la configuration applicative auprès du serveur de configuration :
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
Configuration Spring Cloud
Par convention, la configuration d’une application Spring Boot est centralisée dans le fichier de configuration application.properties (ou application.yml). Via le mécanisme de hiérarchie de contextes, une application Spring Cloud initie un contexte de bootstrap qui charge sa configuration depuis le fichier bootstrap.yml.
Le fichier bootstrap.yml est minimaliste. On y retrouve le nom du microservice et l’URL du serveur de configuration. Exemple issu de vets-service :
spring:
cloud:
config:
uri: http://localhost:8888
application:
name: vets-service
Pendant les développements, l’exécution de vets-service (et des autres microservices) demande à ce qu’un serveur de configuration soit démarré en local sur le port 8888. Au démarrage, le microservice ira récupérer le reste de sa configuration (complétant application.properties/yml et bootstrap.yml) auprès du le serveur de configuration.
Veuillez noter ici que l’URL du serveur de configuration doit être connue et ne peut pas être découverte au runtime.
Serveur de configuration
Le serveur de configuration utilisée par Petclinic est un serveur développé par les ingénieurs de Pivotal. Il fait partie intégrante de l’offre Spring Cloud. Ce serveur peut être mutualisé pour l’ensemble des microservices d’un SI.
Toute la configuration applicative est versionnée dans un dépôt Git. Changer la configuration ne nécessite plus de rebuilder les applications ou de les redéployer. Un simple redémarrage est suffisant. Au travers de l’annotation @RefreshScope ou de l’événement EnvironmentChangeEvent, lorsque l’application a été designée pour, il est même possible de changer à chaud la configuration des beans Spring.
Le serveur de config est packagé sous forme d’un JAR Spring Cloud. Pour créer le module spring-petclinic-config-server, un peu de dév a été nécessaire :
- Générer une application minimaliste Spring Boot (par exemple via https://start.spring.io)
- Inclure une dépendance vers l’artefact spring-cloud-config-server :
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-server</artifactId> </dependency>
- Ajouter l’annotation @EnableConfigServer sur la classe main.
Dans son fichier de configuration bootstrap.yml, on retrouve le port 8888 utilisé précédemment, mais surtout l’URL du repo Git hébergeant les fichiers de configuration :
server.port: 8888
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-petclinic/spring-petclinic-microservices-config
---
spring:
profiles: local
cloud:
config:
server:
git:
uri: file:///${GIT_REPO}
Pendant la phase de développement, pour tester ses changements de configuration, il n’est pas nécessaire de les pousser sur le dépôt Git distant. Le profile Spring « local » permet d’aller chercher les fichiers dans un dépôt Git local au poste de dév en passant ces 2 paramètres à la JVM :
-Dspring.profiles.active=local -DGIT_REPO=/projects/spring-petclinic-microservices-config
Par simplicité, ni l’accès au dépôt, ni l’accès au serveur de configuration n’ont été sécurisés. C’est bien entendu nécessaire en entreprise. Le contenu des fichiers de configuration (comme les mots de passe) peut également être chiffré. Je vous renvoie à la documentation pour consulter toutes les options possibles.
Une fois démarré, le serveur de configuration met à disposition la configuration au travers d’une API REST exposant plusieurs endpoints :
/{application}/{profile}[/{label}]
/{application}-{profile}.yml
/{label}/{application}-{profile}.yml
/{application}-{profile}.properties
/{label}/{application}-{profile}.properties
Pour en revenir avec notre exemple, lors de son démarrage depuis un poste de dév (avec le profile « default » de Spring activé), l’application vets-service récupère sa configuration via un GET sur l’URL http://localhost:8888/vets-service-default.yml
Un navigateur, une commande curl ou Postman renverrait la réponse suivante :
eureka:
instance:
instance-id: ${spring.application.name}:${random.uuid}
logging:
level:
org:
springframework: INFO
management:
security:
enabled: false
petclinic:
database: hsqldb
server:
port: 0
spring:
cloud:
refresh:
refreshable: false
datasource:
data: classpath*:db/hsqldb/data.sql
schema: classpath*:db/hsqldb/schema.sql
jpa:
hibernate:
ddl-auto: none
sleuth:
sampler:
percentage: 1.0
vets:
cache:
heap-size: 100
ttl: 60
Lors du traitement de la requête, le serveur de configuration fusionne le contenu de 2 fichiers du dépôt Git :
- application.yml: la configuration transverse à tous les microservices
- vets-service.yml: la configuration spécifique à l’application vets-service
Le serveur prend également en considération le ou les profiles Spring actifs côté appelant (mais pas celui déclaré dans le application.properties).
Les logs de démarrage de vets-service confirment ce comportement :
c.c.c.ConfigServicePropertySourceLocator : Fetching config from server at : http://localhost:8888
c.c.c.ConfigServicePropertySourceLocator : Located environment: name=vets-service, profiles=[default], label=null, version=0361c87037425c4d4ee4614fe0df06640de479a2, state=null
b.c.PropertySourceBootstrapConfiguration : Located property source: CompositePropertySource {name='configService', propertySources=[MapPropertySource {name='configClient'}, MapPropertySource {name='https://github.com/spring-petclinic/spring-petclinic-microservices-config/vets-service.yml (document #1)'}, MapPropertySource {name='https://github.com/spring-petclinic/spring-petclinic-microservices-config/vets-service.yml (document #0)'}, MapPropertySource {name='https://github.com/spring-petclinic/spring-petclinic-microservices-config/application.yml (document #0)'}]}
Le démarrage de vets-service échoue quelques millisecondes plus tard. Sa configuration est bien chargée, mais il n’arrive pas à s’enregistrer auprès de l’annuaire de service.
Annuaire de service Eureka
Pour communiquer, les microservices doivent savoir se co-localiser. Dans une architecture microservices hébergée dans le Cloud, nous pouvons difficilement anticiper le nombre d’instances d’un même microservice (dépendant de la charge) ni même où elles seront déployées (et donc sur quelle IP et quel port elles seront accessibles). C’est là où le serveur Eureka rentre en jeu : il va mettre en relation les microservices. Chaque microservice va :
- S’enregistrer au démarrage puis donner périodiquement signe de vie (heartbeat toutes les 30 secondes)
- Récupérer l’adresse de leurs adhérences à partir d’un identifiant, en l’occurrence le nom de l’application déclaré via la propriété application.name (ex : vets-service) du boostrap.yml (chargé avant le application.properties)
Eureka fait partie des projets OSS de Netflix supportés par Spring Cloud.
A l’instar de ce qui a été fait pour le serveur de configuration, il est nécessaire de mettre en œuvre un serveur Eureka (module spring-petclinic-discovery-server). Cela se fait très simplement :
- Partir d’une application vierge Spring Boot
- Déclarer l’artefact spring-cloud-starter-netflix-eureka-server
- Ajouter l’annotation @EnableEurekaServer sur la classe main
- Déclarer l’artefact spring-cloud-starter-config et configurer l’adresse du serveur de configuration (idem pour tous les microservices)
Configurer le serveur Eureka par l’intermédiaire du fichier discovery-server.xml (le nom de fichier correspond au nom de l’application spring.application.name) :
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
Nous indiquons au serveur d’opérer dans la zone géographique par défaut et de ne pas s’enregistrer auprès d’autres instances d’Eureka. En production, redonder les instances d’Eureka renforcerait la tolérance aux pannes et lui éviterait d’être un Single Point of Failure (SPOF).
A ce stade, le serveur Eureka peut être démarré.
Chaque microservice doit ensuite intégrer un client Eureka chargé de dialoguer avec le serveur Eureka :
- Commencer par déclarer le starter spring-cloud-starter-netflix-eureka-client
- Sur la classe main du microservice, ajouter l’annotation @EnableDiscoveryClient entraperçu sur la classe VisitsServiceApplication.
L’annotation @EnableDiscoveryClient active l’implémentation Eureka de l’interface Spring Cloud DiscoveryClient chargée d’enregistrer le microservice et de localiser ses pairs. A noter que Spring Cloud supporte d’autres annuaires de service : Consul de Hashicorp et Apache Zookeeper.
Dans les logs de démarrage du microservice vets-service, la phase d’enregistrement Eureka intervient en dernier :
o.s.c.n.eureka.InstanceInfoFactory : Setting initial instance status as: STARTING com.netflix.discovery.DiscoveryClient : Initializing Eureka in region us-east-1 c.n.d.s.r.aws.ConfigClusterResolver : Resolving eureka endpoints via configuration com.netflix.discovery.DiscoveryClient : Disable delta property : false com.netflix.discovery.DiscoveryClient : Single vip registry refresh property : null com.netflix.discovery.DiscoveryClient : Force full registry fetch : false com.netflix.discovery.DiscoveryClient : Application is null : false com.netflix.discovery.DiscoveryClient : Registered Applications size is zero : true com.netflix.discovery.DiscoveryClient : Application version is -1: true com.netflix.discovery.DiscoveryClient : Getting all instance registry info from the eureka server com.netflix.discovery.DiscoveryClient : The response status is 200 com.netflix.discovery.DiscoveryClient : Starting heartbeat executor: renew interval is: 30 c.n.discovery.InstanceInfoReplicator : InstanceInfoReplicator onDemand update allowed rate per min is 4 com.netflix.discovery.DiscoveryClient : Discovery Client initialized at timestamp 1537461549479 with initial instances count: 7 o.s.c.n.e.s.EurekaServiceRegistry : Registering application vets-service with eureka with status UP com.netflix.discovery.DiscoveryClient : Saw local status change event StatusChangeEvent [timestamp=1537461549493, current=UP, previous=STARTING] com.netflix.discovery.DiscoveryClient : DiscoveryClient_VETS-SERVICE/vets-service:3e3fe9e1-071c-447f-94ca-2050dee7af2a: registering service... o.s.s.p.vets.VetsServiceApplication : Started VetsServiceApplication in 10.272 seconds (JVM running for 10.821) com.netflix.discovery.DiscoveryClient : DiscoveryClient_VETS-SERVICE/vets-service:3e3fe9e1-071c-447f-94ca-2050dee7af2a - registration status: 204
Le serveur Eureka vient avec une petite interface de supervision accessible en local à l’adresse http://localhost:8761/. Le statut des différents microservices et le nombre d’instances y sont visibles :
A ce stade, nous avons vu comment faire pour enregistrer un microservice auprès de l’annuaire Eureka, mais pas encore comment fait appel à un microservice depuis un autre microservice.
Appeler un microservice
Dans Petclinic, le microservice front API Gateway centralise les appels aux API REST des 3 microservices back. On peut l’assimiler à un Backend for Frontend. Il permet de gérer les problématiques de CORS tout en assurant l’équilibrage de charge.
Par exemple, lorsque l’utilisateur souhaite consulter l’écran de consultation d’un propriétaire, le code JavaScript du navigateur fait appel à l’URL : http://localhost:8080/api/gateway/owners/1
Le contrôleur REST Spring MVC ApiGatewayController a la responsabilité de traiter cette requête HTTP. Il délègue son traitement au service CustomersServiceClient qui fait à son tour un appel REST au microservice customers-service :
public class CustomersServiceClient {
private final RestTemplate loadBalancedRestTemplate;
public OwnerDetails getOwner(final int ownerId) {
return loadBalancedRestTemplate.getForObject("http://customers-service/owners/{ownerId}", OwnerDetails.class, ownerId);
}
}
Le host de l’URL a une particularité : ce n’est ni un nom de domaine, ni un nom de serveur, ni même une adresse IP. Ici, on utilise l’ID du microservice, celui utilisé pour s’enregistrer auprès du serveur Eureka.
L’autre particularité concerne le nom donné à l’instance du bean implémentant l’interface Spring MVC RestTemplate : loadBalancedRestTemplate.
Dans la configuration Spring du microservice ApiGatewayApplication, le bean RestTemplate est annoté avec l’annotation Spring Cloud @LoadBalanced :
@Bean
@LoadBalanced
RestTemplate loadBalancedRestTemplate() {
return new RestTemplate();
}
De manière transparente pour le développeur, l’annotation @LoadBalanced configure le RestTemplate pour utiliser un répartiteur de charge (load-balancer) côté client. L’implémentation par défaut du LoadBalancerClient est Netflix Ribbon. La classe de configuration LoadBalancerAutoConfiguration se charge de positionner l’intercepteur LoadBalancerInterceptor sur le RestTemplate.
Cet intercepteur va faire appel au service Eureka pour localiser les différentes instances de customers-service disponibles. Il va ensuite appliquer l’algorithme round-robin pour appeler successivement chaque instance et ainsi répartir la charge. D’autres algorithmes sont bien entendu disponible dans Ribbon (ils implémentent tous l’interface IRule).
Remarque : par programmation, grâce à l’annotation @EnableDiscoveryClient, il est possible d’interroger le service Eureka pour récupérer manuellement la liste des instances disponibles et d’exploiter le tuple host/port de SeviceInstance :
@Autowired
private DiscoveryClient discoveryClient;
…
List<ServiceInstance> instances = discoveryClient.getInstances("customers-service");
Router les appels
Le microservice front API Gateway centralise les appels du navigateur. Bien qu’il puisse jouer un rôle d’agrégateur, la plupart des appels sont directement destinés aux microservices back : on a du 1 pour 1. Développer des contrôleurs REST chargés d’aiguiller la requête aux back n’a que peu d’intérêt.
Pour éviter tout boilerplate code, Spring Cloud Netflix propose d’utiliser le proxy Zuul. Activable via l’annotation @EnableZuulProxy, Zull va permettre de forwarder les requêtes reçues par l’API Gateway vers les microservices back. Il fait office de reverse proxy (comme le ferait un Apache ou un Nginx).
Pour bénéficier de Zuul, il est nécessaire d’ajouter au module spring-petclinic-api-gateway le starter spring-cloud-starter-netflix-zuul :
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>
La configuration des routes est fait dans le fichier api-gateway.yml dont voici un extrait :
zuul:
prefix: /api
ignoredServices: '*'
routes:
vets-service: /vet/**
visits-service: /visit/**
customers-service: /customer/**
api-gateway: /gateway/**
La requête http://localhost:8080/api/vet/vets est automatiquement routée par Zuul vers http://vets-service/vets. En interne, le proxy utilise Eureka pour localiser les instances de vets-setvice.
Console d’administration
Le serveur Eureka propose une interface permettant de consulter la liste des microservices enregistrés et disponibles. C’est bien, mais insuffisant pour administrer toutes les applications d’un SI.
Développé par codecentric AG, Spring Boot Admin est un projet communautaire permettant de monitorer et d’administrer des applications Spring Boot déployées en production. Développée en Vue.js, l’IHM de Spring Boot Admin fait appel aux Actuators de Spring Boot pour connaître l’état des applications. Supportant Spring Cloud, il s’interface directement à Eureka pour récupérer la liste des différentes applications Spring Boot.
Parmi les fonctionnalités proposées par Spring Boot Admin, on peut lister :
- La consultation du statut de chaque application
- La récupération de différentes métriques : JVM, mémoire, Micrometer.io, pool de connections, cache …
- La consultation des informations sur le build : date de création, sha1 du commit Git, GAV Maven …
- La gestion des logs : téléchargement des fichiers de logs, modification à chaud du niveau de logs
- La gestion des heapdump : consultation et téléchargement
- En cas de changement d’état d’une application, des notifications par mail, Slack, Hipchat, PageDuty …
Petclinic intègre Spring Boot Admin dans le module spring-petclinic-admin-server.
Parti d’une application Spring Cloud rudimentaire, 2 dépendances Maven ont été ajoutées :
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-server</artifactId>
<version>${spring-boot-admin.version}</version>
</dependency>
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-server-ui</artifactId>
<version>${spring-boot-admin.version}</version>
</dependency>
L’annotation @EnableAdminServer a été ajoutée sur la classe main :
@Configuration
@EnableAutoConfiguration
@EnableAdminServer
@EnableDiscoveryClient
public class SpringBootAdminApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBootAdminApplication.class, args);
}
}
Côté client, une dépendance vers Jolokia a été ajoutée dans les pom.xml. Jolokia permet d’exposer sur HTTP les beans JMX.
<dependency>
<groupId>org.jolokia</groupId>
<artifactId>jolokia-core</artifactId>
</dependency>
Spring Boot Admin s’appuie sur les différents Actuators proposés par Spring Boot : heapdump, threadump, loggers, scheduledtasks … Depuis Spring Boot 2, pour des raisons de sécurité, seuls les Actuators health et info sont exposés par défaut. Il est nécessaire d’activer explicitement les autres actuators. Dans le fichier de configuration application.yml, a été ajoutée la ligne suivante : management.endpoints.web.exposure.include: « * »
Une fois démarré, Spring Boot Admin est accessible sur l’URL http://localhost:9090/ :
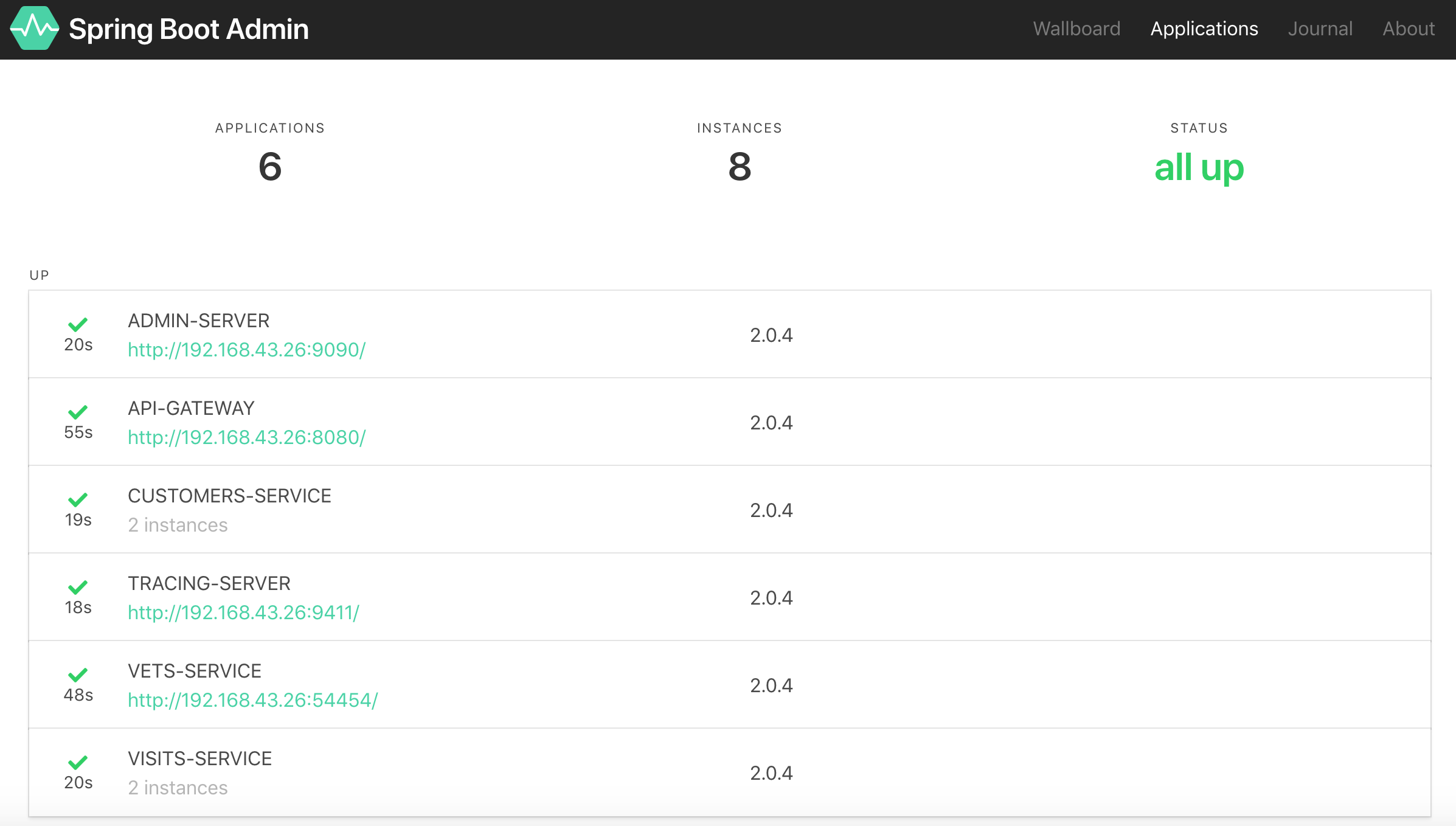
En sélectionnant une des 2 instances de customers-service, on accède aux différents outils d’administration, dont par exemple ici le suivi de la consommation de ressources (mémoire, thread, CPU) :
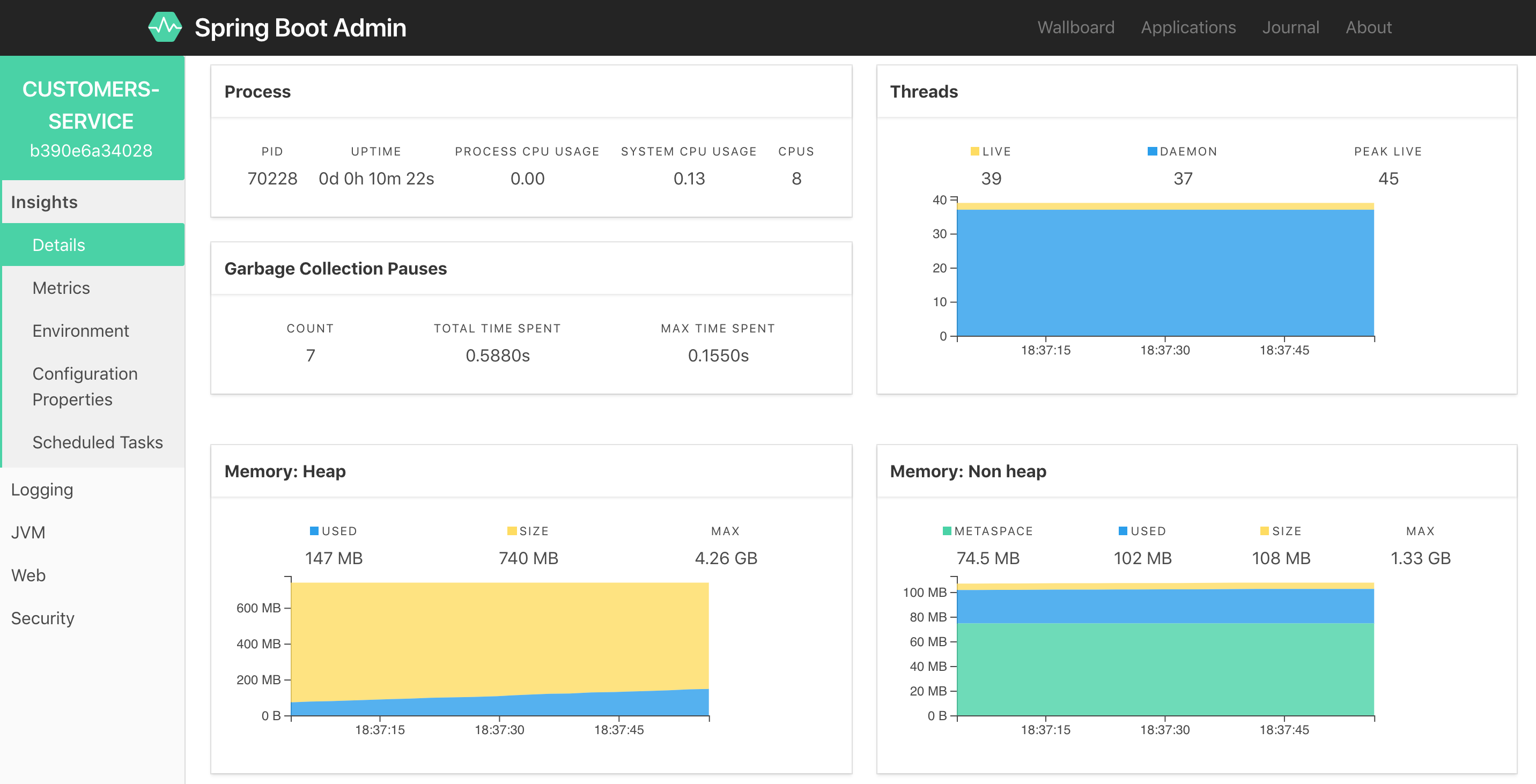
Spring Boot Admin n’est pas limité à l’affichage d’informations dans de joli graphes. Un administrateur peut aller changer le niveau de log d’un logger Logback. Le changement de niveau est immédiat. Aucun redémarrage n’est nécessaire.

Traces distribuées
Afin de pouvoir tracer et debugger les appels HTTP entre nos microservices, un mécanisme de traces distribuées a été mis en œuvre à l’aide du client Spring Cloud Sleuth et du serveur Zipkin. L’interface graphique du serveur Zipkin permet de les consulter les piles d’appel et les adhérences entre microservices.
En pratique, le serveur Zipkin se déploie dans une image Docker. Sa personnalisation n’est plus supportée par l’équipe de Dév. Dans Petclinic, par simplicité, son intégration a été réalisée dans le module spring-petclinic-tracing-server sous forme d’une application Spring Boot configurée avec l’annotation dépréciée @EnableZipkinServer.
L’interface est disponible sur l’URL : http://localhost:9411/zipkin/
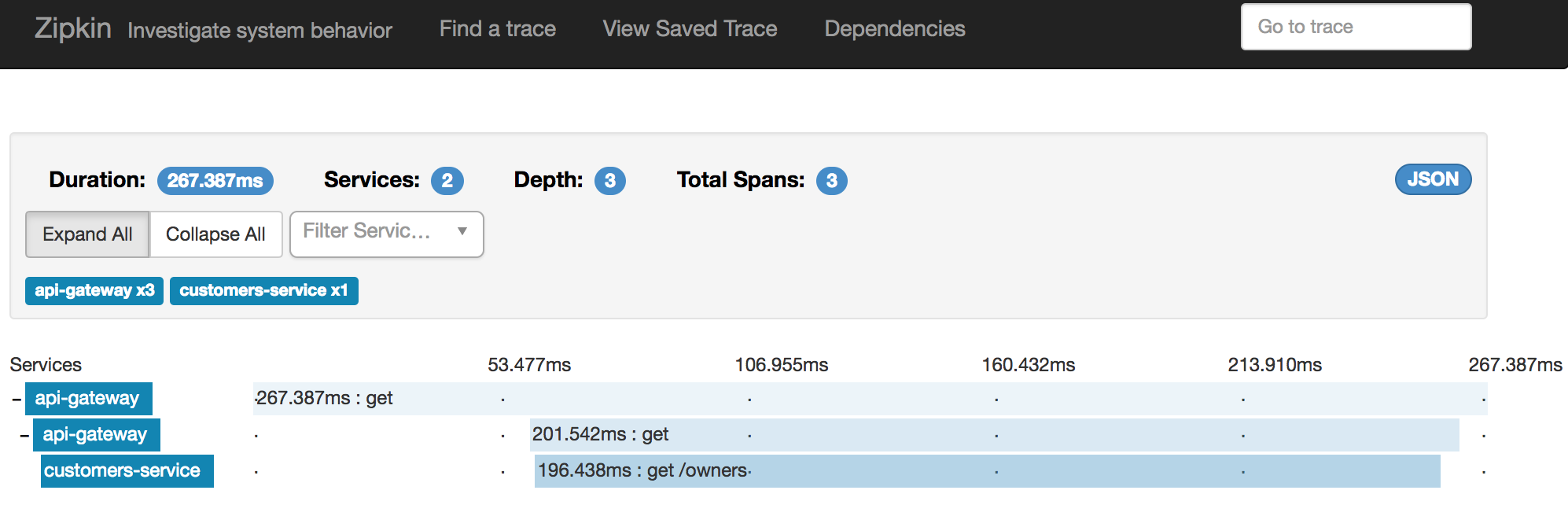
Sur une période de temps, Zipkin sait générer un diagramme de dépendances entre microservices :

Containerisation
L’architecture de Petclinic repose sur un ensemble de 8 microservices, tous basés sur Spring Boot. Livrables sous forme d’un simple JAR, leur déploiement ne nécessite qu’un simple JRE Java 8.
Pour déployer Petclinic chez un fournisseur Cloud proposant une offre de type Container as a Service (CaaS), les microservices doivent être packagés sous forme d’images Docker. Petclinic vient avec un exemple de packaging Docker pour un déploiement local (sur le poste de dév) à l’aide de Docker Compose.
Dans le POM parent, le profile Maven buildDocker permet de construire les images Docker à l’aide du plugin Maven de Spotify : ./mvnw clean install -PbuildDocker
Une fois les images construites, on peut toutes les démarrer en une seule commande : docker-compose up
Les images Docker reposent toutes sur le même Dockerfile (à noter que l’ENTRYPOINT est redéfini dans le docker-compose.yml):
FROM openjdk:8
VOLUME /tmp
ADD https://raw.githubusercontent.com/vishnubob/wait-for-it/master/wait-for-it.sh wait-for-it.sh
RUN bash -c 'chmod +x wait-for-it.sh'
ARG ARTIFACT_NAME
ARG EXPOSED_PORT
ADD ${ARTIFACT_NAME}.jar /app.jar
ENV SPRING_PROFILES_ACTIVE docker
RUN bash -c 'touch /app.jar'
EXPOSE ${EXPOSED_PORT}
ENTRYPOINT ["java", "-XX:+UnlockExperimentalVMOptions", "-XX:+UseCGroupMemoryLimitForHeap", "-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
Introduits depuis Java 8 update 131, les flags UnlockExperimentalVMOptions et UseCGroupMemoryLimitForHeap ordonnent à la JVM d’utiliser ¼ de la mémoire allouée à l’OS (si Xmx non spécifié). Ils fonctionnent de pair avec le paramètre mem_limit spécifié dans le docker-compose.yml pour chaque image Docker.
Une autre spécificité du Dockerfile concerne l’utilisation du script wait-for-it.sh. En effet, l’ordre de démarrage des microservices est important : le serveur de Configuration doit être démarré en premier, suivi de l’annuaire de Services et du serveur Zipkin. Les autres microservices peuvent ensuite être démarrés simultanément. Le script wait-for-it.sh permet de se mettre en attente de la disponibilité d’une application web. Dans le docker-compose.yml, l’entrypoint du container discovery-server attend que le config-server soit démarré avant de démarrer sa JVM :
entrypoint: [« ./wait-for-it.sh », »discovery-server:8761″, »–timeout=60″, »–« , »java », …]
Les applications Spring Boot démarrent avec le profile Spring docker. Dans le fichier de configuration Spring Cloud de chaque microservice, ce profile écrase des valeurs par défaut utilisées pour un déploiement hors container.
Si l’on prend comme exemple un extrait du fichier de configuration customers-service.yml :
---
spring:
profiles: docker
zipkin:
baseUrl: http://tracing-server:9411
server:
port: 8081
eureka:
client:
serviceUrl:
defaultZone: http://discovery-server:8761/eureka/
On remarque que :
- Le port HTTP est hard-codé et fixé à 8081. En effet, le Docker Compose ne démarre qu’une seule instance de customers-service. Son numéro de port n’a pas besoin d’être alloué dynamiquement par Spring Boot.
- L’URL du serveur Eureka et du serveur Zipkin référencent les paramètres container_name et ports du docker-compose.yml.
Conclusion
Ce long billet nous aura permis de voir comment mettre en place une architecture microservices à l’aide de Spring Boot, Spring Cloud et Netflix OSS. Comme support, nous nous serons appuyés sur l’application démo « Spring Petclinic Microservices » créée par Maciej Szarliński. De nombreuses améliorations sont d’ores et déjà prévues :
- Récupération des métriques à l’aide de Micrometer et Prometheus
- Support des JDK 10 et 11
- Utilisation du client Feign à la place de RestTemplate
Ce projet est communautaire : vos contributions sont les bienvenues.
Enfin, pour celles et ceux que cela intéresse, sachez que d’autres fork de Spring Petclinic existent. Je vous renvoie vers cet ancien billet pour une présentation générale.
Ressources :
- Repo Git spring-petclinic/spring-petclinic-microservices de l’application Spring Petclinic Microservices
- Repo Git spring-petclinic/spring-petclinic-microservices-config de la configuration de Spring Petclinic Microservices
- Microservices a definition of this new architectural term (Martin Fowler)
- The rise of Java microframeworks (E4developer)
- Spring Cloud Config official documentation
- Appréhendez l’architecture Microservices (OpenClassrooms)
Bonjour,
je te remercie pour ce blog.
Ce lâ fait 3 mois que j’apprends Spring, j’ai déja appris en détails Spring (Ioc, AOP, MVC, JDBC). actuellement j’apprends Hibernate et Spring Cloud. Le problème que j’ai trouvé, est la masse de technologies qui existent. Si on prends par exemple la couche persistance de données on trouve Spring-Jdbc, Spring-data, JPA, Hibernate…, et je me sens confondu, je trouve des diffucultés pour apprendre toutes ces technologies.
pourriez vous me citer les choses que je dois donner une plus grande priorité. Par exemple pour la couche de persistence? pour ce qui Spring cloud?
J’ai 4 mois pour me preparer encore pour des entretiens pour un poste de développeur Java(Spring).
Merci
Bonjour Tajjini,
Il m’est difficile de vous conseiller d’apprendre telle technologie de persistance plutôt qu’une autre. Tout dépend de l’entreprise dans laquelle vous allez travailler et de ses choix techniques. Du fait du peu de développeurs expérimentés en ORM sur le marché (Hibernate, Spring Data JPA), certaines entreprises sont retournées à du JDBC (avec Spring JDBC Template dans le monde Spring, Spring Data JDBC étant très récent). Dans le monde des ORM, Hibernate domine. Mais vous pouvez très bien être amené à travailler sur une base NoSQL (Cassandra, MongoDB). Si tel est le cas, Hibernate et JDBC ne vous serviront pas.
Si vous avez le choix de la stack technique pour une application de gestion adossée à une base relationnelle, Spring Data JPA est un must have. L’application officielle Spring Petclinic s’appuie notamment dessus : https://github.com/spring-projects/spring-petclinic
Pour ce qui est de Spring Cloud, il me semble que connaître Spring Boot est une pré-requis. Ensuite, je vous recommanderai de comprendre comment fonctionne la gestion de configuration avec Spring Cloud Config et la découverte des services avec @EnableDiscoveryClient et Eureka ou Consul.
Bon courage à vous dans votre apprentissage.
Antoine
Bonjour,
Bravo pour ce Tuto
Grand merci pour votre effort de rédaction.
Salut,
Je voudrais savoir s’il est possible de mettre à jour un service tel que le service client, et de le déployer sans nécessairement construire l’ensemble du projet et effectuer à nouveau le menu de composition.
Bonjour Santos,
Par simplicité, les différents services de l’application démo https://github.com/spring-petclinic/spring-petclinic-microservices sont hébergés dans un même repo git. Leurs modules Maven ont le même cycle de vie. Dans une architecture d’Entreprise, chaque microservice aurait son propre repo et son propre cycle de vie.
Pour autant, tu peux rebuilder un microservice (jar + image Docker) en allant dans le sous-répertoire correspondant. Le fichier docker-compose.yml référence la version latest donc devrait la prendre en compte.
J’espère avoir répondu à ta question.
Antoine
Hi,
Firstly, thank you for this great tutorial. you said that » In an Enterprise architecture, each microservice would have its own repo and its own lifecycle. » If i want to write one microservice with spring and another service with flask, then this api gateways and discovery servers does not work for my flask service. In this type of service which api gateways and service discovery tools should i use?
Hi Kaya,
You could use this eureka client written in python https://pypi.org/project/py-eureka-client/ to easily integrate your python microservices with the Spring Cloud stack.
The Spring Cloud Gateway could forward your HTTP requests to your Flask application (and any web application).
Regards
Antoine
Thank you for quick answer Antoine. Simply, i will create an eureka server with spring cloud , then i am going to implement eureka clients in different languages like python, go , dotnet etc. Is this a right pattern ? Can eureka manages this types of architecture?
Best regards.
Kaya
The Eureka Server is implemented in Java. But it exists a lot of implementations of Eureka client.
See those resources for Donet : https://altkomsoftware.pl/en/blog/service-discovery-eureka/ or GO : https://pkg.go.dev/github.com/ArthurHlt/go-eureka-client#readme-go-eureka-client
An alternative could be to use HashiCorp Consul https://www.consul.io/ I never tested it.
Bonjour,
Merci pour ce billet !
J’ai une petite question, si un service devient indisponible comment fait-on pour qu’il ne soit plus enregistrer au prêt du dicovery server et que par conséquent le loadbalancer ne redirige plus les requêtes vers lui ?
Peut être à partir d’un circuit breaker, mais il me avoir compris qu’il permettait surtout de rediriger les appels trop long et éventuellement d’éviter de les rappeler pendant un certain temps (mais j’ai peut être pas tout saisie encore).
Bonjour Nuanda,
Merci pour ton retour. Cet article mériterait d’être révisé car depuis 3 ans, l’eco-système Spring Cloud a pas mal évolué. Je vais y réfléchir.
Pour répondre à ta question, de mémoire, à son démarrage, un service s’enregistre auprès du Discovery Server et récupère l’annuaire des autres services qu’il met en cache. L’IHM d’Eureka permet de consulter la liste des services enregistrés.
Les services envoient régulièrement un hearthbeat au Discovery Server.
Lorsque le service s’arrête proprement, il se désenregistre du Discovery Server. Lors d’un arrêt brutal du service, le Discovery Server ne reçoit plus de heartbeat et en conclue que le service est tombé.
En parallèle, un service rafraichit régulièrement son cache de services en interrogeant le Discovery Server.
Annoté avec @LoadBalanced, le RestTemplate route les appels vers les services connus. Lorsque plusieurs instances du même service existent, il peut répartir la charge. En cas d’indisponibilité du service avant que le Discovery Server ne le prévienne, je suppose qu’il le retire provisoirement de son cache ? Ce point serait à vérifier.