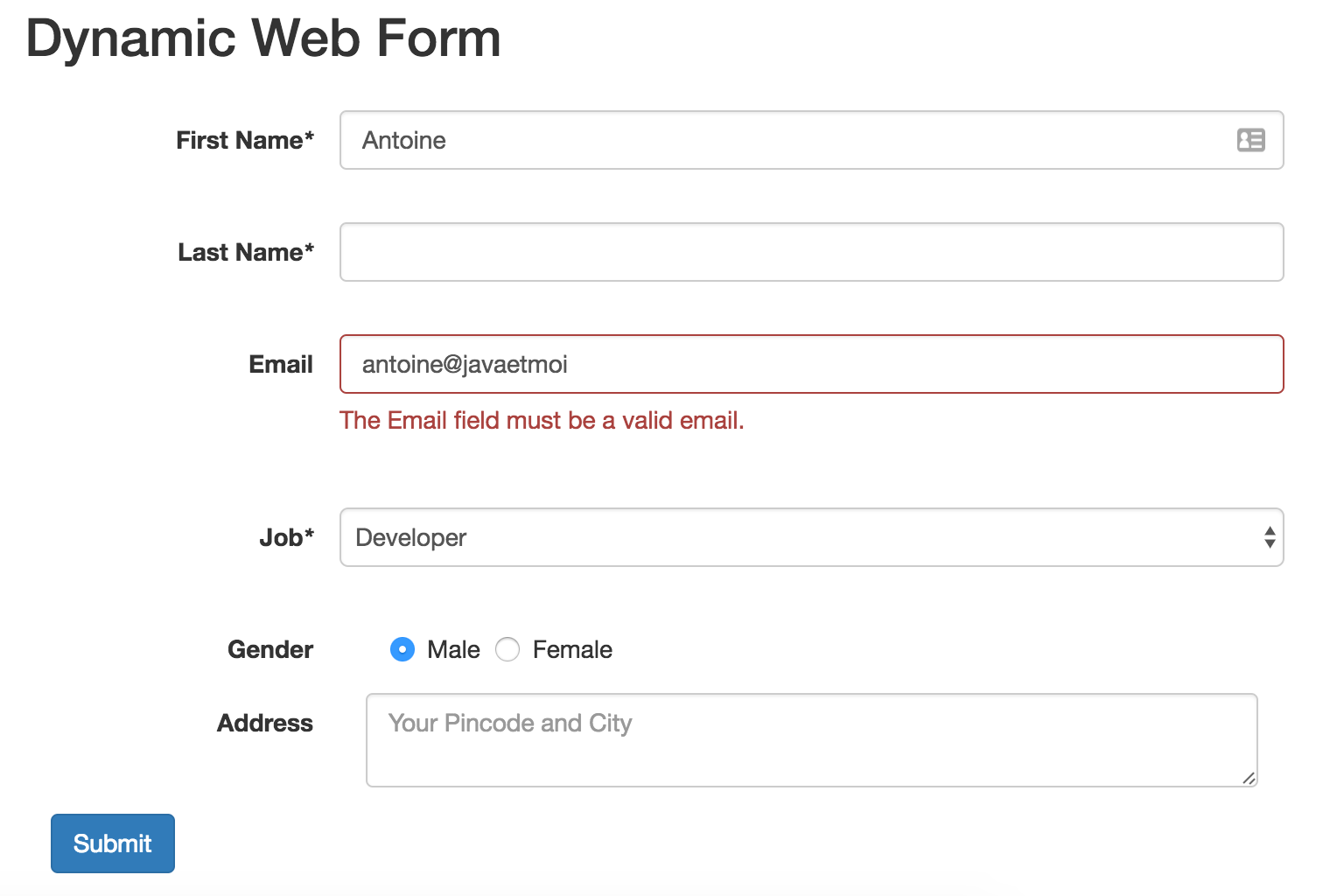
Lorsqu’on développe dans son coin une démo basée sur une nouvelle techno, il est fréquent d’avoir besoin de données de tests. Soit on se les construit à la main, soit on en récupère sur Internet. Le mouvement Open Data et les API mises à disposition par les grands du Web permettent de récupérer des données en temps réel. Dans les conférences, nombre de démos live utilisent les API de Twitter ou de Github. Ces données sont généralement formatées en JSON. Une connexion réseau est alors nécessaire.
Lorsqu’on développe dans son coin une démo basée sur une nouvelle techno, il est fréquent d’avoir besoin de données de tests. Soit on se les construit à la main, soit on en récupère sur Internet. Le mouvement Open Data et les API mises à disposition par les grands du Web permettent de récupérer des données en temps réel. Dans les conférences, nombre de démos live utilisent les API de Twitter ou de Github. Ces données sont généralement formatées en JSON. Une connexion réseau est alors nécessaire.
Dans le cadre d’une série d’articles sur Elasticsearch et AngularJS, j’ai eu le besoin d’indexer des données de manière offline. Cherchant une source de donnée musicale, j’ai opté pour MusicBrainz qui, à l’instar d’IMDb pour le cinéma, est une plateforme ouverte collectant des méta-données sur les artistes, leurs albums et leurs chansons puis les mettant à disposition du publique. Cette plateforme est composée d’une base de données relationnelles et d’une interface web permettant d’effectuer des recherches, de consulter les données et de participer à l’enrichissement de la base. Last.fm, The Guardian ou bien encore la BBC s’interfacent avec MusicBrainz.
Dans l’article Elastifiez la base MusicBrainz sur OpenShift, je proposais 2 méthodes pour installer la base de données : récupérer une VM ou un dump de la base PostgreSQL. Dans les 2 cas, la procédure d’installation demandait une intervention humaine.
Ce billet vous en propose une 3ième : automatiser l’installation de base de données à l’aide de Docker. Après quelques lignes de commande et un peu de patience le temps de l’import du dump PostgreSQL, vous pourrez vous connecter localement à la base musicale contenant des données à jour.
Continuer la lecture de Docker file de la database MusicBrainz →