
Dans ce billet, nous verrons comment configurer en Java le contexte Spring d’une application basée sur Spring MVC, Spring Security, Spring Data JPA et Hibernate, et cela sans utiliser la moindre ligne de XML.
Personnellement, je n’ai rien contre la syntaxe XML à laquelle j’étais habitué. D’autant la verbosité de la configuration avait considérablement diminué grâce à l’introduction des namespaces XML et des annotations. Avant d’utiliser la syntaxe Java sur une application d’entreprise, j’étais même sceptique quant aux gains qu’elle pouvait apporter. Aujourd’hui, je comprends mieux son intérêt et pourquoi les projets du portfolio Spring tels Spring Integration 4.0, Spring Web Service 2.2 ou bien Spring Security 3.2 proposent dans leur dernière version un niveau de configuration Java iso-fonctionnel avec leur équivalent XML. Sans compter que le support de la configuration Java leur ouvre la porte d’une intégration plus poussée à Spring Boot, le nouveau fer de lance de Pivotal.
Tous les articles par Antoine
14 prises de notes à Devoxx France 2014
En attendant que les vidéos des différentes conférences de l’édition 2014 de Devoxx France soient mises en ligne sur Parleys et en complément des supports déjà mis en ligne par certains Speakers, je mets librement à votre disposition les différentes notes que j’ai pu prendre sur mon laptop.
Les sujets sont variés : de Docker à Angular JS, en passant par Java 8. Certaines pourront être lues de manière autonome ; je pense par exemple au quickie Outils pour manager une équipe et à la conférence 33 things your want to do better. Pour être exploitables en l’état, d’autres notes demanderont à ce que vous ayez assisté à la conférence ou que vous ayez pu récupérer les supports de présentation.
 Continuer la lecture de 14 prises de notes à Devoxx France 2014
Continuer la lecture de 14 prises de notes à Devoxx France 2014
Comprendre AngularJS en le recodant à Devoxx France 2014
Lors de Devoxx France 2013, je découvrais AngularJS lors de l’Université sur AngularJS animée par Thierry Chatel. Enthousiasmé par ce framework, je vous faisais ici même une restitution de cette Université. Depuis un an, j’ai poursuivi mon initiation en codant un front-end pour Elasticsearch avec Angular. Lorsque j’ai découvert que Matthieu Lux et Olivier Huber proposaient le Hand’s-on-Lab « Angular JS from scratch : comprendre Angular en le refaisant de zéro » à Devoxx France 2014, j’y ai vu l’occasion ou jamais d’approfondir mes connaissances et de découvrir les mécanismes se cachant derrière la magie d’Angular.

Ce workshop a eu un beau succès : une salle comble 10 minutes avant son début et une place sur le podium des meilleures sessions de la matinée.
Pour coder les différents exercices sans avoir à se tourner régulièrement vers les solutions, de solides connaissances en JavaScript étaient nécessaires : héritage par prototype, constructeur, portée du this, couteau suisse underscore (each, clone, isEqual) …
Par ailleurs, pour apprécier la démarche, une connaissance minimaliste d’Angular me paraissait également indispensable.
Durant les 3 heures du Lab, nous avons pu implémenter 11 des 12 étapes prévues initialement (la dernière étant en bonus). Timing parfaitement respecté. Si vous n’avez pas eu la chance d’assister à cette présentation et si vous disposez de 3 heures devant vous, je vous conseille de tenter de le réaliser chez vous.
Les slides du workshop, le code source de départ, les solutions et les tests unitaires sous Jasmine sont disponibles dans le repo Github angular-from-scratch de Zenika.
Continuer la lecture de Comprendre AngularJS en le recodant à Devoxx France 2014
Utilisez Hibernate 4.3 sous JBoss 5 avec Spring 4
Dans mon précédent billet, je vous expliquais comment réintroduire le support de VFS 2 abandonné dans Spring Framework 4.0. Et ceci, dans l’optique de pouvoir déployer mon application dans le serveur d’application JBoss 5.1 EAP.
Outre ce problème survenant lors de la détection de beans Spring dans le classpath, la montée de version de Spring 3.2 à Spring 4 a révélé un autre problème lié au format VFS de JBoss. Cette fois-ci, c’est le framework Hibernate 4.3 qui n’arrive pas à détecter les entités JPA du classpath.
Certifié conforme à Java EE 5, JBoss 5.1 EAP utilise Hibernate 3.3 comme implémentation de JPA 1. Dans mon cas, Hibernate 4.3 est utilisé en mode standalone et est donc directement embarqué dans les librairies de mon EAR. La configuration JPA 2.1 est assurée par le support JPA offert par Spring, et plus particulièrement par la classe LocalContainerEntityManagerFactoryBean.
Support du VFS 2 de JBoss 5 dans Spring 4
Ce billet solutionne un problème rencontré lors de la montée de version du famework Spring de la version 3.2 à la version 4.0. En effet, le déploiement d’une application sous JBoss 5.1 EAP échouait dès l’initialisation du contexte Spring. Plus précisément, une exception était levée lorsque Spring scanne le classpath à la recherche de beans Spring annotés par les annotations @Repository, @Service, @Controller …
Comme le montre la pile d’appel complète ci-dessous, l’exception java.lang.ClassNotFoundException: org.jboss.vfs.VFS est encapsulée dans l’exception java.lang.IllegalStateException: Could not detect JBoss VFS infrastructure
Ce problème ne m’était initialement pas apparu lors des développements sous Eclipse avec le plugin JBoss Tools pour WTP : Spring n’a aucun mai à trouver les beans d’un WAR ou d’un EAR explosé. Cette erreur s’est manifestée lors du déploiement manuel de l’EAR dans le répertoire deploy de JBoss puis du démarrage du serveur par la commande run.bat.
Plusieurs JBoss Messaging pour une même base
Ce billet ne devrait intéresser que les développeurs Java ou administrateurs JBoss en charge de la configuration de JBoss Messaging, le broker JMS intégré aux versions 4.3 et 5.x du serveur d’application JBoss EAP.
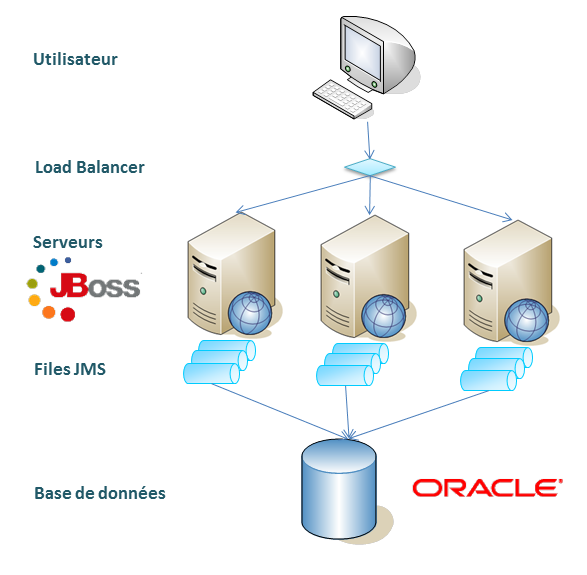
Pour fil conducteur, prenons l’exemple d’une application Java EE déployée dans un pseudo cluster JBoss où, par choix d’architecture technique, chaque serveur JBoss est autonome. A ce titre, les sessions HTTP ne sont pas partagées entre les différents serveurs JBoss ; le répartiteur de charge fonctionne en affinité de session De plus, chaque serveur dispose de ses propres files JMS (clustering JBoss Messaging non mis en œuvre). Les messages JMS sont persistés dans une base de données, Oracle dans notre cas.
La persistance des messages peut se faire de 2 manières :
- Utiliser un schéma Oracle différent pour chaque serveur JBoss du cluster
- Utiliser le même schéma pour tous les serveurs JBoss du cluster
JBoss Messaging supportant le multi-tenancy, cet article explique comment mettre en œuvre la 2ième solution.
Continuer la lecture de Plusieurs JBoss Messaging pour une même base
Tester le code JavaScript de vos webapp Java
![]() Vous développez une application web en Java. Le couche présentation est assurée typiquement par un framework MVC situé côté serveur : Spring MVC, Struts 2, Tapestry ou bien encore JSF. Votre projet est parfaitement industrialisé : infrastructure de build sous maven, intégration continue, tests unitaires, tests Selenium, analyse qualimétrique via Sonar.
Vous développez une application web en Java. Le couche présentation est assurée typiquement par un framework MVC situé côté serveur : Spring MVC, Struts 2, Tapestry ou bien encore JSF. Votre projet est parfaitement industrialisé : infrastructure de build sous maven, intégration continue, tests unitaires, tests Selenium, analyse qualimétrique via Sonar.
A priori, vous n’avez rien à envier à la richesse grandissante de l’écosystème JavaScript, de l’outillage et des frameworks MV* côté clients. Et pourtant, quelque chose vous manque cruellement. En effet, depuis que RIA et Ajax se sont imposés, votre application Java contient davantage de code JavaScript qu’il y’a 10 ans. S’appuyant sur des librairies telles que jQuery ou Underscore, ce code JavaScript est typiquement embarqué dans votre WAR. Pour le valider, les développeurs doivent démarrer leur conteneur web et accéder à l’écran sur lequel le code est utilisé. Firebug ou Chrome sont alors vos meilleurs amis pour la mise au point du script.
Ce code JavaScript n’est généralement pas documenté. Le tester manuellement demande du temps. Les modifications sont sources d’erreur. Tout changement est donc périlleux. Si, à l’instar de vos tests JUnit pour vous classes Java, vous disposiez de tests JavaScript, vous en seriez comblés. Or, c’est précisément ce qu’il vous manque. Et c’est là où Jasmine et son plugin maven viennent à votre rescousse.
Continuer la lecture de Tester le code JavaScript de vos webapp Java
Memory Leak du client CXF
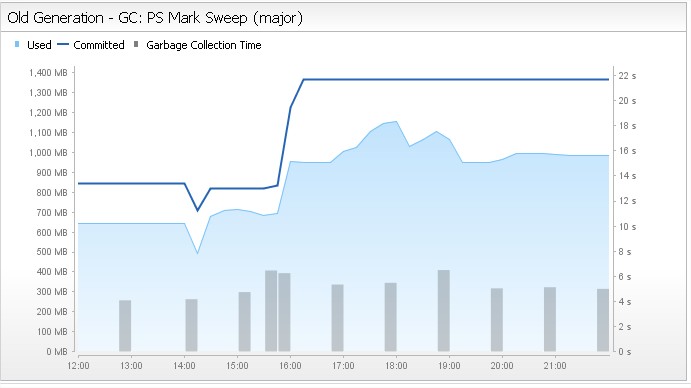
Les tests de charge d’une nouvelle fonctionnalité m’a récemment permis de détecter un comportement inattendu de CXF s’apparentant à une fuite mémoire. Fusion de Celtix et de XFire, le framework CXF propose une implémentation cliente et serveur de web services SOAP et REST. Le comportement suspect concerne la partie cliente d’un web service SOAP avec pièce-jointes.
Les symptômes ont été observés dans les conditions suivantes. Un tir de charge avec JMeter simule l’upload de fichiers de 4 Mo. Trente utilisateurs connectés simultanément uploadent des fichiers PDF. D’une durée de 5mn, le scénario fonctionnel mettant en jeu l’upload de fichiers est réitéré pendant 3h. A l’issu du tir, aucune erreur technique ou fonctionnelle n’est remontée. Par contre, l’analyse de l’empreinte mémoire est suspecte : non seulement cette nouvelle fonctionnalité a nécessité davantage de mémoire que lors des tirs précédents, mais surtout : la mémoire n’est jamais libérée, même après l’expiration des sessions utilisateurs.
Développer et industrialiser une web app avec AngularJS
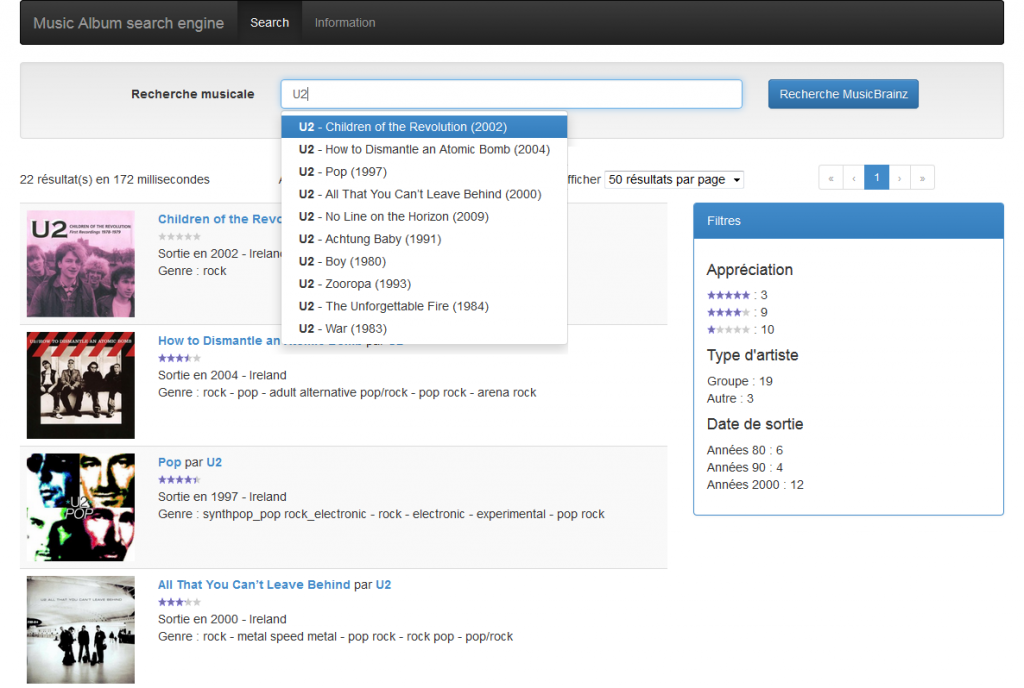
Au travers du billet Elastifiez la base MusicBrainz sur OpenShift, je vous ai expliqué comment indexer dans Elasticsearch et avec Spring Batch l’encyclopédie musicale MusicBrainz. L’index avait ensuite été déployé sur le Cloud OpenShift de RedHat.
Une application HTML 5 était mise à disposition pour consulter les albums de musique ainsi indexés. Pour m’y aider, Lucian Precup m’avait autorisé à adapter l’application qu’il avait mise au point pour l’atelier Construisons un moteur de recherche de la conférence Scrum Day 2013.
Afin d’approfondir mes connaissances de l’écosystème JavaScript, je me suis amusé à recoder cette application front-end en partant de zéro. Ce fut l’occasion d’adopter les meilleures pratiques en vigueur : framework JavaScript MV*, outils de builds, tests, qualité du code, packaging …
Au travers de ce article, je vous présenterai comment :
- Mettre en place un projet Anguler à l’aise d’Angular Seed, Node.js et Bower
- Développer en full AngularJS et Angular UI Bootstrap
- Utiliser le framework elasticsearch-js
- Internationaliser une application Angular
- Tester unitairement et fonctionnellement une application JS avec Jasmine et Karma
- Analyser du code source JavaScript avec jshint
- Packager avec Grunt le livrable à déployer
- Utiliser l’usine de développement JavaScript disponible sur le Cloud : Travis CI, Coversall.io et David
Le code source de l’application est bien entendu disponible sur GitHub et testable en ligne.
Retour d’expérience sur les problématiques Elasticsearch
« Près de 2 ans passés chez un client en tant que référent technique d’un middle de recherche basé sur le moteur de recherche Elasticsearch, il me paraît aujourd’hui opportun de vous faire part des différentes problématiques rencontrées au cours des développements et de son exploitation. »
En 2 versions majeures et une montée de version d’Elasticsearch, les problématiques abordées ont été nombreuses : occupation mémoire, ré-indexation sans interruption de service, Split Brain, IDF et partitionnement. Prêts pour ce retour d’expérience ? »
Continuer la lecture de Retour d’expérience sur les problématiques Elasticsearch