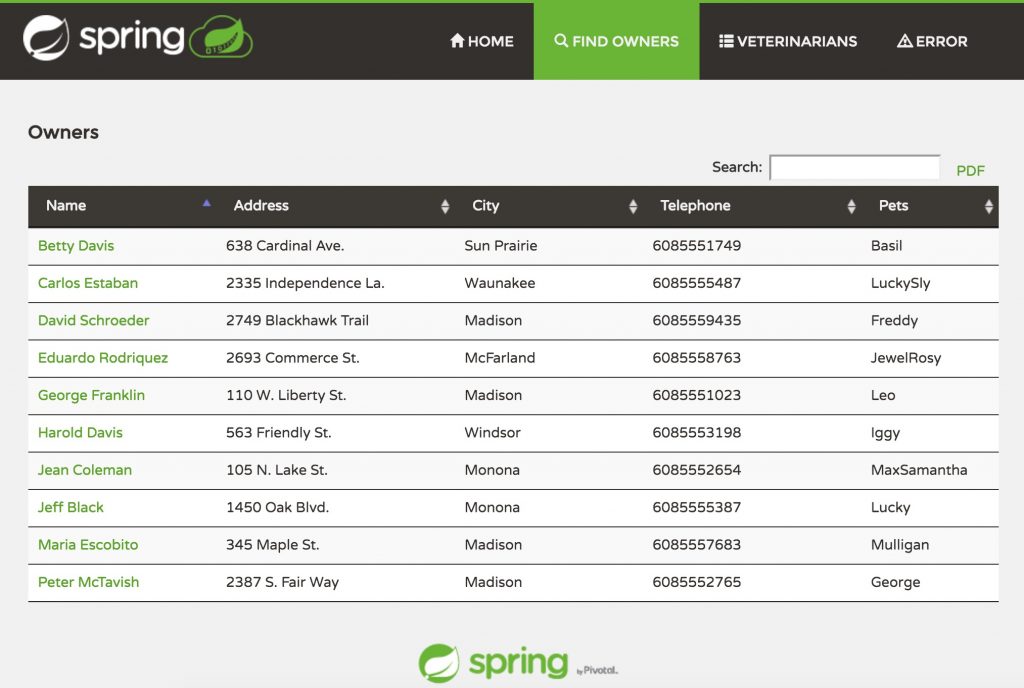
L’application démo Spring Petclinic a été conçue pour montrer comment le framework Spring peut être utilisé pour développer une application web secondée par une base de données relationnelle. En somme, rien de révolutionnaire. Mais c’est ce qui fait tout son intérêt : présenter une architecture logicielle respectant l’état de l’art d’une application conçue avec Spring.
Ce billet a pour objectif de vous présenter cette récente initiative puis de vous présenter les différents forks d’ores et déjà disponible dans l’organisation Spring Petclinic. Mais avant cela, remontons le temps.
Par le passé, j’ai publié 2 images Docker sur le registre Docker Hub, l’équivalent du Maven Central Repository pour Docker : un client MySQL et une base PostgreSQL MusicBrainz. Ces images étaient construites puis publiées automatiquement à partir d’un dépôt GitHub contenant un Dockerfile et, éventuellement, un script Shell.
Dans mon précédent article sur Spring Boot, je vous détaillais le chemin de migration de l’application démo Spring Petclinic vers Spring Boot. Intéressons-nous aujourd’hui aux fondamentaux : qu’est-ce qu’est Spring Boot ? Et comment fonctionne-t-il ? Vous trouverez des éléments de réponse dans la présentation suivante. J’y décris les grands principes de Spring Boot. Puis j’essaie de démystifier le fonctionnement de l’auto-configuration. Enfin, je montre comment Spring Boot permet de simplifier encore davantage vos tests.
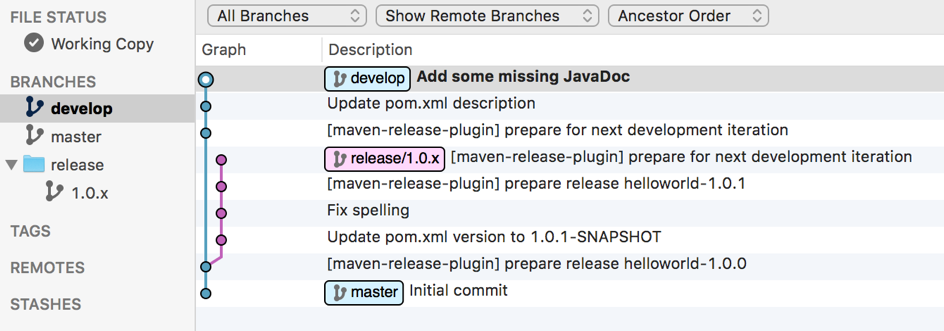
L’utilisation conjointe de Maven pour réaliser des release et de git-flow peut s’avérer laborieuse.
En effet, lorsque vous travaillez avec des branches (quelque soit le SCM), une bonne pratique veut que chaque branche possède son propre numéro de version. Afin d’éviter des collisions de nommage, cette pratique devient indispensable lorsque vous utilisez un serveur d’intégration continue pour publier les artefacts construits dans un repo Maven.
Une fois une branche crée à partir d’une autre, chaque branche vit sa vie. Des releases Maven peuvent être réalisées de part et d’autre. Là où cela devient tendu, c’est lorsque vous devez reporter les commits d’une branche vers une autre. Des conflits de merge sur le numéro de version Maven apparaissent alors inévitablement. Lorsque votre application multi-modules comporte 15 pom.xml, c’est 15 conflits qu’il va falloir gérer manuellement. Il est effectivement risqué de conserver aveuglément la version du pom.xml local ou distant, car d’autres changements (et vrais conflits) peuvent se produire dans d’autres sections du pom.xml.
Comme cas d’études, prenons l’exemple du repo Git helloworld :
Cela fait un an que je contribue activement à la maintenance de l’application Spring Petclinic. Développée initialement par les créateurs du framework Spring, Juergen Hoeller et Rob Harrop, cette application démo a évolué au fur et à mesure des montées de version du framework. Elle est passée d’une approche full XML, à une approche mixte annotations + XML. Une branche est également disponible pour la configuration Java.
Récemment, nous avons mis à disposition une branche basée sur Spring Boot 1.4.0. L’objectif de ce billet est de vous expliquer quels ont été les impacts d’une telle migration.
J’ai eu l’opportunité d’assister à une journée de découverte de la plateforme Cloud de Google. Dispensée dans les locaux parisiens de Google, cette formation d’une journée était animée par Didier Girard, Google Developer Expert et Directeur Général Délégué de Sfeir. Ce fut l’occasion de découvrir la diversité des offres proposées par la Google Cloud Platform et de pouvoir les comparer à celles, plus médiatisées, d’autres géants du web tels Amazon (AWS) et Microsoft (Azure).
Large, la gamme de services Google Cloud Platform est répartie en 4 offres :
Big Data: BigQuery, Pub/Sub, Dataflow, Dataproc, Datalab
Machine Learning: Vision API, Machine Leargning, Speech API, Translate API
Cet article se focalisera sur l’offre Compute. Mais avant d’aller plus loin, arrêtons-nous un moment sur ce qui est l’une des forces de la plateforme Cloud de Google : son infrastructure.
Bien que Java 8 soit sorti il y’a 2 ans, tous les développeurs n’ont pas eu encore la chance de pouvoir utiliser, en entreprise, tous les concepts issus de la programmation fonctionnelle et qui ont été introduits dans cette version majeure : expressions lambda, interfaces fonctionnelles, méthodes par défaut, Optional, références de méthode, Streams …
Pourtant, Java 8 est à nos portes : des projets de migration de serveur d’application se terminent, les socles d’entreprise se mettent à jour, des frameworks exploitent ces nouveautés (ex : JUnit 5) … Et on va enfin pouvoir exploiter à bon escient toutes ces nouvelles fonctionnalités. Mais avant cela, une mise à niveau est indispensable. Et c’est dans cet objectif que j’ai récemment initié mes collègues aux Streams.
A partir d’un jeux de données réduit (une liste de 3 clients), j’ai implémenté quelques règles de gestion à la fois en Java 7 avec des boucles et en Java 8 avec des Streams, histoire de leur montrer la différence.
Voici la présentation que j’ai animée auprès de mes collègues afin de leur faire un retour suite à ma participation à Devoxx France 2016. Le leitmotiv était « 1 conférence appréciée => 1 slide ». Au menu : Angular 2, ECMASript 2015, Kakfa, Spring Cloud, architecture StackOverflow, Jenkins pipeline, React, revues de code et documentation.
Pour vous aider à choisir quelle conférence visionner sur la chaîne Devoxx FR 2016 de Youtubeou pour vous remémorer certaines chose, je mets librement à votre disposition les différentes notes que j’ai pu prendre sur mon laptop.
Les sujets sont variés : des Microservices avec Spring Boot et Spring Cloud, du Big Data avec Kafka et Elasticsearch, du Front End avec ECMAScript 2015 et React, du Java 8 et 9 ou bien encore de la méthodologie avec les revues de code et de la living documentation.
Certaines notes pourront être lues de manière autonome ; je pense par exemple au quickie Comment rater ses revues de code ? et à la conférence Stack Overflow behind the scenes. Pour être exploitables en l’état, d’autres notes demanderont à ce que vous ayez assisté à la conférence ou que vous ayez pu récupérer les supports de présentation.
Ce billet s’adresse à celles et ceux qui n’ont pas pu assister à ce Lab et qui ont envie de découvrir Angular 2. Il s’appuie sur les ressources mises à disposition par les speakers.
En7 étapes, vous développerez une application de Quizz avec la beta 11 d’Angular 2.
Nous utilisons des cookies pour vous garantir la meilleure expérience sur notre site web. Si vous continuez à utiliser ce site, nous supposerons que vous en êtes satisfait.