L’utilisation conjointe de Maven pour réaliser des release et de git-flow peut s’avérer laborieuse.
En effet, lorsque vous travaillez avec des branches (quelque soit le SCM), une bonne pratique veut que chaque branche possède son propre numéro de version. Afin d’éviter des collisions de nommage, cette pratique devient indispensable lorsque vous utilisez un serveur d’intégration continue pour publier les artefacts construits dans un repo Maven.
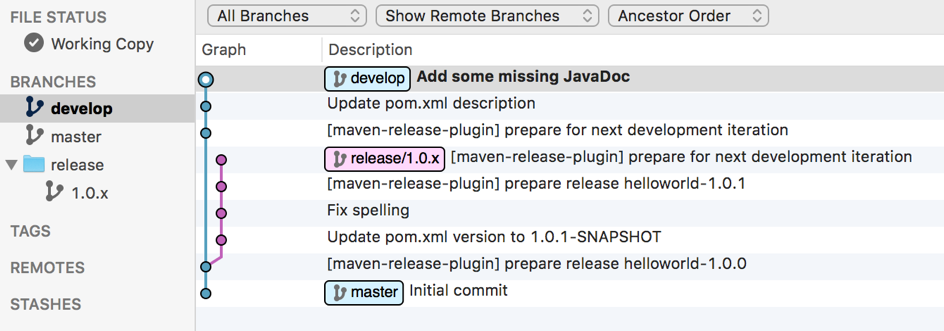
Une fois une branche crée à partir d’une autre, chaque branche vit sa vie. Des releases Maven peuvent être réalisées de part et d’autre. Là où cela devient tendu, c’est lorsque vous devez reporter les commits d’une branche vers une autre. Des conflits de merge sur le numéro de version Maven apparaissent alors inévitablement. Lorsque votre application multi-modules comporte 15 pom.xml, c’est 15 conflits qu’il va falloir gérer manuellement. Il est effectivement risqué de conserver aveuglément la version du pom.xml local ou distant, car d’autres changements (et vrais conflits) peuvent se produire dans d’autres sections du pom.xml.
Comme cas d’études, prenons l’exemple du repo Git helloworld :