
![]() Ce billet a pour origine un commentaire posté dans mon précédent billet et dans lequel Laurent demandait un retour d’expérience sur l’utilisation de frameworks Java de mapping objet vers objet tels Dozer ou ModelMapper.
Ce billet a pour origine un commentaire posté dans mon précédent billet et dans lequel Laurent demandait un retour d’expérience sur l’utilisation de frameworks Java de mapping objet vers objet tels Dozer ou ModelMapper.
Dans l’architecture d’une applicative n-tiers, une couche de mapping objet / objet peut intervenir à plusieurs niveaux :
- En entrée ou en sortie d’un web service SOAP afin de convertir en objet métier les DTO générés à partir du WSDL, ou inversement.
- Entre la couche de présentation et la couche de services métiers lorsque la première expose des DTO et la seconde travaille avec des objets métiers.
- Entre la couche de services métiers et la couche d’accès aux données afin de mapper les entités persistances en objets métiers.
Dans le premier exemple, le développeur n’a guère le choix. Dans les 2 autres, il s’agit d’un choix d’architecture.
L’introduction d’une couche de mapping n’est pas un choix à prendre à la légère : ayant pour objectif de découpler les couches, elle complexifie l’application et peut détériorer ses performances. Le choix d’en introduire une et d’utiliser un framework pour faciliter sa mise en œuvre n’est pas non plus évident.
Ce billet est découpé en 2 parties :
- Une première dressant les avantages et les inconvénients d’utiliser Dozer par rapport à une approche manuelle,
- et une seconde présentant les résultats d’un micro-benchmark comparant plusieurs frameworks : Dozer, Orika, Selma, MapStruct et ModelMapper.
Tableau comparatif Dozer vs mapping manuel en Java
Extrait d’un retour d’expérience, le tableau ci-dessous dresse les avantages et les inconvénients de Dozer par rapport à une approche manuelle. A vous de pondérer chaque avantage / inconvénient en fonction de vos exigences.
| Dozer | Java | |
| Avantages |
|
|
| Inconvénients |
|
|
En fonction de votre expertise, ce tableau pourrait être adapter avec d’autres frameworks.
Quelque soit l’approche choisie (framework ou code manuel), seuls des tests unitaires permettront de valider le mapping. Ne pouvant être automatisés, ces tests s’avèrent malheureusement longs et fastidieux.
Micro-benchmark
Ne trouvant aucun comparatif récent sur les performances des frameworks de mapping, j’ai créé sur GitHub le projet java-object-mapper-benchmark. Ce dernier utilise JMH (Java Microbenchmarking Harness) pour réaliser un micro-benchmark entre Dozer, Selma, ModelMapper, Orika, MapStruct et un mapping écrit manuellement.
Le diagramme ci-dessous présente résultats obtenus avec la configuration suivante :
- OS: MacOSX
- CPU: Core i7 2.8GHz 6MB cache × 4 cores
- RAM: 16GB
- JVM: Oracle 1.8.0_25 64 bits
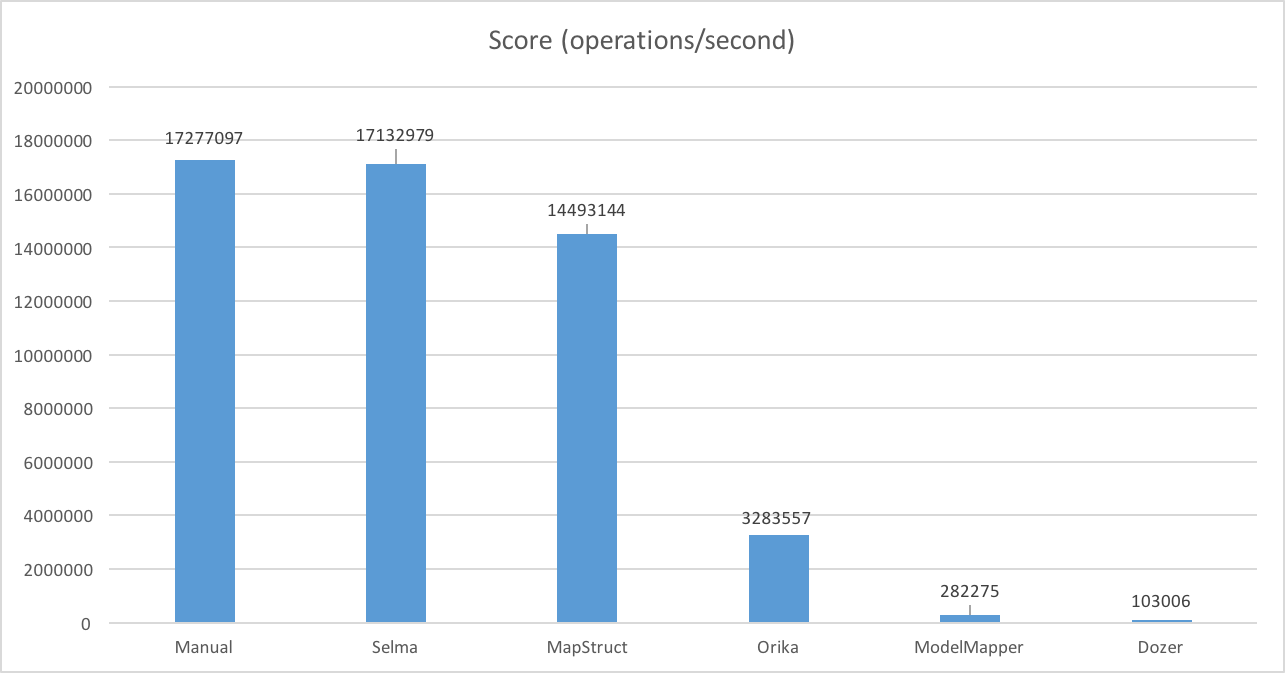
Comme on pouvait s’y attendre, les performances du code écrit à la main sont les meilleures.
Selma et MapStruct se rapprochent le plus des performances d’un code écrit manuellement. Ce résultat s’explique par le fait qu’ils génèrent le code source à l’aide de l’Annotation Processor introduit par Java 6 (JSR-269).
Basés sur l’introspection de code, Dozer et ModelMapper sont peu performants.
Entre ces 2 catégories, on retrouve Orika qui utilise au runtime l’API Java Compiler pour générer le code du mapping.
Pour exécuter vous même le benchmark, Maven, un JDK et 3 lignes de commandes suffisent :
git clone git://github.com/arey/java-object-mapper-benchmark.git mvn clean install java -jar target/benchmarks.jar
Conclusion
En 2015, l’utilisation d’un framework de mapping objet / objet basé sur la génération de code plutôt que sur l’introspection semble préférable. Non seulement les performances sont bien meilleures, mais le couplage avec le framework est faible puisqu’il est possible de le supprimer et de conserver dans votre SCM le code généré. Selma et MapStruct sont les 2 gagnants du benchmark.
Encore une fois, avant de partir sur une telle approche, prenez un temps de réflexion. Des entités métiers annotées avec Bean Validation et traversant l’ensemble des couches restent l’architecture la plus simple à mettre en œuvre. Je suis déjà intervenu sur une application où une couche de mapping avait été mise en œuvre dès le départ pour des raisons de découplage, puis retirée au fur et à mesure car sa plus value était trop faible.
Références :
Bonjour Antoine,
Un énorme merci pour ce benchmark auquel je ne m’attendais pas. Il est d’autant plus instructif que les écarts sont conséquents entre les différentes solutions techniques retenues par ces frameworks.
Je vais me ruer sur le code aimablement mis à disposition pour mieux percevoir ce qu’implique la mise en oeuvre de chaque solution.
Merci encore pour cette agréable surprise
Salut Antoine,
ça fait un bail, je passais par là et je suis tombé sur cet article. Une très bonne surprise pour moi, j’en était resté à Dozer et ModelMapper et il est vrai que j’étais un peu ennuyé par le coût lié à l’introspection. Je ne connaissais pas les solutions basées sur la génération de code (Selma et MapStruct donc) et c’est une découverte pour moi, et une bonne surprise. Orika était dans ma todo-list mais en lointaine position 😉
En tout cas merci pour cette contribution. Et n’hésites pas à développer ton point de vue sur Bean Validation, mon intuition sur ce point rejoignait ton conseil et pour être honnête comme je n’ai plus trop eu à traiter d’archi JEE depuis quelque temps je n’ai pas approfondi et j’ai la flemme (pas de cas d’usage dans les tuyaux …).
a+
Billet très interessant sur la coparaison des frameworks de factory automatique ! cela confirme mes tests JMH. merci.
Bonjour et merci pour ce billet très intéressant.
Il y un point que j’aimerai ajouter, il s’agit de la compatibilité avec lombok.
Lombok est une librairie utilisée pour générer les getter/setter à la compilation via l’annotation processor. C’est très utile mais cela pose problème si on utilise map struct ou selma. La seule solution de contournement est de déplacer ses entités et ses dtos dans un module maven séparée…
Orika semble compatible directement avec lombok, c’est je pense un avantage à considérer.
Pour info, en relançant ces benchs aujorud’hui (le 19/01/2017) avec les dernières versions, on remarque que 1 an et demi après les écarts de performances sont les mêmes.
JMapper qui n’est pas présenté ici mais qui était présent sur le Dépot est juste en dessous de Mapstruct.
Si on part du principe que ces benchs ont été fait le 16/09/2015, il est intéressant de noter que Dozer est le seul qui n’a pas évolué :
orika 1.4.6 (May, 2015) 1.5.0 (Dec, 2016)
dozer 5.5.1 (Apr, 2014) idem !!
modelmapper 0.7.5 (Sep, 2015) 0.7.7 (Oct, 2016)
mapstruct 1.0.0.CR2 (Aug, 2015) 1.1.0.Final (Nov, 2016)
selma 0.12 (Apr, 2015) 0.15 (Jul, 2016)
jmapper 1.4.2 (Sep, 2015) 1.6.0.1 (Apr, 2016)
Pour info voici les résultats :
Benchmark Score Error Units
manual 13090067,67 83122,6 ops/s
selma 13062938,01 117979,558 ops/s
mapStruct 11822100,04 167796,608 ops/s
jmapper 10966729,53 115245,214 ops/s
orika 2867276,161 23691,535 ops/s
modelMapper 203917,852 1816,008 ops/s
dozer 65224,54 630,094 ops/s
Merci Nicolas pour ces benchs mis à jour. Le projet GitHub proposait déjà des résultats plus récents : https://github.com/arey/java-object-mapper-benchmark Et JMapper a été ajouté par un contributeur. N’hésite donc pas à soumettre une PR.
Bonjour,
Je pense que le test est faussé par le fait qu’Orika génère les classes de mapping au démarrage de l’application. Dans le cadre du benchmark ce processus est appelé à chaque itération d’où les performances médiocre d’Orika. Dans un projet classique c’est phase n’est faite qu’une fois démarrage de l’application.
Nous utilisons Orika sur mon projet et j’étais plutôt surpris de vos résultats j’ai donc lancé votre projet en debug sur les classes Orika et en effet à chaque itération le context Orika est recréé.
Bonjour Guillaume,
Dans le microbenchmark, le code d’initialisation est réalisé dans le constructeur du test unitaire, à savoir ici OrikaMapper.
Je m’attendrais donc à ce que le code de mapping soit généré par Orika une fois pour toute, comme sur une application classique. En effet, le constructeur du TU n’est appelé qu’une seule et unique fois par JMH.
Afin de pouvoir investiguer sur un probable problème de codage du benchmark d’Orika, pourrais-tu ouvrir une issue sur le repo https://github.com/arey/java-object-mapper-benchmark et préciser qu’elle est la méthode de génération qui est appelée plusieurs fois (voir systématiquement) ?
Merci
Antoine
Bonjour Antoine,
J’ai continué un peu dans mes tests et au final Orika génère une fois ces classes pour chaque benchmark donc si on configure 1 warmup 2 itérations, la génération se fera une fois lors du warmup ce qui n’affecte pas les performances donc vu que seul les itérations sont prises en compte pour le calcul.
J’ai donc fait mes bench avec 1 warmup et 200 itérations et les résultats laisse quand même Orika loin derrière.
Guillaume
Dommage que ce ne soit pas très pratique à utiliser avec lombok