
Utiliser les IA Génératives avec Java

Au-delà des simples chatbots
Conférence : Devoxx France 2024
Date : 17 avril 2024
Speakers : Abdellfetah Sghiouar (Google), Cédrick Lunven (DataStax)
Format : Deep Dive (3h)
Slides : https://github.com/datastaxdevs/conference-2024-devoxx-france/blob/main/slides.pdf
Vidéo Youtube : https://www.youtube.com/watch?v=6n8JysFyVA8
Repo GitHub : https://github.com/datastaxdevs/conference-2024-devoxx-france
Dans ce Deep Dive de 3h (anciennement nommé Université à Devoxx France), Abdellfetah Sghiouar et Cédrick Lunven nous expliquent comment intégrer l’intelligence artificielle générative (la fameuse GenAI) dans nos applications Java, et ceci sans expertise en machine learning ou en Python (ce qui tombe bien). Après nous avoir initié aux Large Language Models (LLMs) et aux techniques de prompting, ils nous apprennent à coder en Java avec LangChain4J et Spring AI pour utiliser le LLM Gemini de Google dans nos projets Java.
L’approche Retrieval Augmented Generation (RAG) est illustrée par son intégration avec des bases de données vectorielle comme Apache Cassandra, ceci pour générer des réponses avec nos propres données. Les Developer Advocates de Google et de DataStax nous donnent des stratégies pour minimiser les erreurs et les hallucinations des LLMs. Les modèles multimodaux (LMM) plus avancés seront également introduits.
Cédrick est Developer Advocate chez DataStax
Il y’a 10 ans, il s’est fait connaitre par la communauté en créant le projet ff4j.
Ces dernières années, il a énormément travaillé sur Cassandra. Cédrick contribue aux projets OpenSource Langchain4j et Spring AI. Je l’ai personnellement rencontré dans le cadre du projet Spring Petclinic Reactive.
Abdel est Developer Advocate chez Google
Expert en Kubernetes, il travaille notamment sur le déploiement des solutions d’IA sur k8s.
Introduction
Abdel souligne le rôle prépondérant de Google dans le domaine de l’IA Generative.
- La GenAI a émergé en 2017 avec l’invention du modèle Transformer par Google
- En 2018, Google a créé le modèle de langage BERT qui a permis d’améliorer les performances en traitement automatique des langues (NLP en anglais).
- En 2019, création de AlphaFold permettant de prédire comment une protéine se développe à partir de leur séquence en acides aminés. Là où un doctorant passé toutes ses études à prédire la structure d’une protéine, AlphaFold l’a fait pour toutes les protéines sur la terre
- 2019 : Google ouvre en open source le modèle text-to-text Transfer Transformer.
- 2021 : Google introduit LaMDA, un modèle de langage conçu spécifiquement pour améliorer les interactions conversationnelles entre les humains et les systèmes d’IA
- 2022 : sorti du modèle de langage PaLM
- 2023 : sorti de PalM 2
- 2024 : lancement du chatbot Gemini (anciennement connu sous le nom de Bard)
Abdel poursuit sa présentation par un rappel des termes utilisés dans l’IA.
L’IA englobe les différentes techniques permettant de reproduire le raisonnement humain.
Le Machine Learning (ML) inclue le Deep Learning qui inclue à son tour l’IA Générative.
Le ML nécessite des données d’entrainement et fait appel à la Data Science.
Le GenAI inclue Image Gen et LLM.
Les LLM sont des réseaux de neurones basés sur l’architecture Transformers. Ils sont capables de reconnaitre, prédire et générer du langage.
Un LLM génère un mot à la fois. Il calcule la probabilité du prochain mot en se basant sur une approche statistique.
Le fonctionnement d’un LLM et de l’IA générative est particulièrement bien illustré sur le site du Financial Times ig.ft.com/generative-ai
Le site https://lifearchitect.ai/models/ référence la taille de nombreux LLM :

PaLM 2 a été entrainé sur 340 milliards de paramètres et, en ce mois d’avril 2024, bat tous les records.
Se référer à l’article Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance
D’après Abdel, les LLMs se sont démocratisés grâce à la disponibilité de cartes graphiques moins onéreuses et à la possibilité d’entrainer son modèle dans le Cloud.
Autre hypothèse formulée : les investisseurs croient désormais en l’IA !
Cas d’utilisation des LLM en 2024 :
- Langage : écrire du texte, faire des résumé, extraction de texte, créer un chat, classification, recherche, idéation
- Code : génération de code (boilerplate), complétion de code (compagnon/assistant), chat, conversion de code
- Speech : speech-to-speech (traduction), text-to-speech
- Vision : génération d’images, édition, captioning, image Q&A, image search, génération des transcripts de vidéos (comme à Devoxxx France 2024 ;-)
Google propose de nombreuses offres regroupées dans le portfolio Vertex AI :

La première démo en Java de ce Deep Dive commence par l’utilisation de Vertex AI en ajoutant la dépendance maven com.google.cloud:google-vertexai

La classe Demo01_VertexClientChat fait appel à Gemini Pro pour répondre à quelques questions :
@Test
void testChat() throws Exception {
try (VertexAI vertexAI = new VertexAI(GCP_PROJECT_ID, GCP_PROJECT_LOCATION)) {
GenerateContentResponse response;GenerativeModel model = new GenerativeModel("gemini-pro", vertexAI);
ChatSession chatSession = new ChatSession(model);response = chatSession.sendMessage("Hello.");
System.out.println(ResponseHandler.getText(response));response = chatSession.sendMessage("What are all the colors in a rainbow?");
System.out.println(ResponseHandler.getText(response));response = chatSession.sendMessage("Why does it appear when it rains?");
System.out.println(ResponseHandler.getText(response));
}
}
Une seconde démo demande au LLM multimodal gemini-vision-pro de décrire la photo d’un coucher de soleil. Le code envoie simultanément au LLM l’image et la question. Le code Java dépend du client Java Gemini et donc de Vertex AI.
Extrait de la classe Demo02_VertexClientVisionPro :
@Test
void testVision() throws Exception {
// Load the image
byte[] imageBytes;// = Files.readAllBytes(Paths.get(imageName));
String resourcePath = "/img1.png"; // Resource path in the classpathtry (InputStream is = Demo02_VertexClientVisionPro.class.getResourceAsStream(resourcePath)) {
assertThat(is).isNotNull();
imageBytes = is.readAllBytes();
System.out.println("Image bytes read successfully. Length: " + imageBytes.length);
try (VertexAI vertexAI = new VertexAI(GCP_PROJECT_ID, GCP_PROJECT_LOCATION)) {
GenerativeModel model = new GenerativeModel("gemini-pro-vision", vertexAI);
GenerateContentResponse response = model.generateContent(
ContentMaker.fromMultiModalData(
"What is this image about?",
PartMaker.fromMimeTypeAndData("image/jpg", imageBytes)
));System.out.println(ResponseHandler.getText(response));
}
} catch (IOException e) {
System.out.println("Error reading the image file.");
}
}
Gemini
Gemini est le modèle d’IA le plus performant de Google Deep Mind. C’est un modèle multimodale pouvant traiter à la fois du texte, des images et de la vidéo.
Une version Nano est en cours d’incorporation dans Flutter afin d’utiliser la carte graphique du téléphone.
Gemini 1.5 accepte en entrée un livre d’un million de mots. On est loin des premiers prompts limités à quelques centaines de mots.

3 adresses permettent de tester Gemini :
- https://console.cloud.google.com/vertex-ai/model-garden :
- https://ai.google.dev/ : nécessite une clé
- https://ai.google.dev/examples
Démo possible sur https://gemini.google.com/app avec un simple compte Google. Exemple « Quelle est la hauteur de la tour Eiffel ? »

Gemma
Gemma est un modèle OpenSource mis à disposition par Google. Basé sur Gemini, Gemma est téléchargeable depuis HuggingFace. On peut le déployer n’importe où et l’utiliser en Java.
Abdel poursuit ce talk par une démo de la webapp bed-time-stories.web.app créée par Guillaume Laforge et qui permet de générer une histoire pour les enfants. La démo utilise Vertex AI. Abdel utilise Gemma avec quelques commandes curl pour générer une histoire.
Cedrick reprend la main.
Langchain4j
Le projet ollama permet de faire tourner des LLM en local sur son poste de dév.
On peut installer ollama sur Mac, Linux et Windows : https://ollama.com/download
Ollama vient avec une CLI permettant de récupérer un modèle de LLM comme gemma:2b et gemma:7b.
Commande permettant de faire tourner un modèle :
ollama run gemma:7b
Nul besoin de compte (mais peut-être d’une carte Nvidia ?)
Une fois le modèle démarré, on peut l’interroger à base d’une simple commande curl :
curl http://localhost:11434/api/generate -d '{
"model": "gemma:7b",
"prompt": "Pourquoi le ciel est bleu ?"
}'
Plutôt que de passer par curl ou d’utiliser en Java un RestTemplate, Cédric propose d’utiliser la librairie Langchain4j pour faire cette demande.
Langchain4j est une implémentation de Langchain, bibliothèque populaire du monde Python et JavaScript.
Le code suivant est extrait de la classe _21_GemmaChat:
@Test
void talkWithGemma() {
ChatLanguageModel gemma = OllamaChatModel.builder()
.baseUrl("http://localhost:11434/api/")
.modelName("gemma:7b")
.build();System.out.println(gemma.generate("Present yourself , the name of the model, who trained you ?"));
}
L’interface ChatLanguageModel vient de langchain4j-core et la classe OllamaChatModel vient de langchain4j-ollama.
Langchain4j sait manipuler des images. La classe _14_ImageModel_GenerateTest montre comment faire générer une photo d’un coucher de soleil sur une plage de Malibu au LLM Vertex AI.
Cette fois-ci, on utilise la librairie langchain4j-vertexai avec le builder VertexAiImageModel.
D’autres classes d’abstraction de langchain4j existent : LanguageModel, ImageModel
Langchain4j est le leader fournissant le modèle théorique. Tous les fournisseurs de LLM implémentent le langage model, créent une Pull Request et la soumettent à la communauté. Particulièrement doués en IA, les chinois contribuent également.
Voici les LLM supportés par Lanchain4j :

Cédric continue le talk par une démo utilisant langchain4j-gemini avec le modèle StreamingChatLanguageModel et l’appel au builder VertexAiGeminiStreamingChatModel.
Se référer au test _10_LanguageModelSayHello
Spring AI
Plus jeune et développé par l’équipe Spring, le framework Spring AI est un concurrent de Langchain4j.
Cédrick nous montre un HelloWorld en Spring Boot basé sur Gemini:
@SpringBootTest
class _01_LanguageModel_SayHelloTest {@Autowired
private VertexAiGeminiChatClient client;@Value("classpath:/prompts/system-message.st")
private Resource systemResource;@Test
void roleTest() {
String request = "Tell me about 3 famous pirates from the Golden Age of Piracy and why they did.";
String name = "Bob";
String voice = "pirate";
UserMessage userMessage = new UserMessage(request);
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemResource);
Message systemMessage = systemPromptTemplate.createMessage(Map.of("name", name, "voice", voice));
Prompt prompt = new Prompt(List.of(userMessage, systemMessage));
ChatResponse response = client.call(prompt);
System.out.println(response.getResult().getOutput().getContent());
}}
La classe _01_LanguageModel_SayHelloTest montre l’utilisation de classes d’abstraction comme UserMessage, Message, Prompt ou bien encore ChatResponse.
La configuration du LLM est centralisée dans le fichier application.properties :
spring.ai.vertex.ai.gemini.projectId=devoxxfrance
spring.ai.vertex.ai.gemini.location=us-central1
spring.ai.vertex.ai.gemini.chat.options.model=gemini-pro
spring.ai.vertex.ai.gemini.chat.options.temperature=0.8
spring.ai.vertex.ai.gemini.chat.options.topK=2
spring.ai.vertex.ai.gemini.chat.options.topP=0.9
spring.ai.vertex.ai.gemini.chat.options.maxTokens=100
#spring.ai.vertex.ai.gemini.credentialsUri=
Prompt Engineering
La seule commande envoyée à un LLM est une ligne de texte, le fameux prompt.
Quelques bonnes pratiques permettant d’interagir avec le LLM nous sont données :

Comme contraintes, il peut être intéressant de demander au LLM de ne pas répondre aux questions dont il ne connait pas la réponse. Cela permet de limiter les hallucinations. Exemple de contexte : « Si l’on te pose des questions qui sort des objectifs qu’on t’a donné, répond que tu ne sais pas. »
Avec un prompt assez long, on peut souvent contourner les frontières du LLM.
En complément de cette phrase, on envoie au LLM différents paramètres.

Température comprise entre 0 et 1 : niveau d’expression qu’on donne au LLM
0 : plus précis, robotique
1 : créatif, hallucination possible
Le choix de la température dépend des uses cases. Dans le cas d’une recherche documentaire par exemple, on emploie une température basse.
Top P favorisant la diversité et la créativité.
Jusqu’à combien de mots tu peux mettre des réponses avec un degré de probabilité
Spécifiez une valeur faible pour les réponses moins aléatoires et une valeur plus élevée pour les réponses plus aléatoires
Top K similaire au Top P, mais en moins dynamique
Tokens : taille de la réponse
Plus la réponse est longue, plus le cout augmente et sa précision baisse.
Des techniques avancées de prompt engineering permettent d’améliorer la rédaction des prompts.
Few-Shot Learning
On envoie au LLM quelques exemples afin qu’ils comprennent mieux ce que l’on souhaite lui demander.

Chain of Thoughts
Chaine de pensée : donner un raisonnement pour que le LLM trouve le résultat.

CoT + Self consistency
Le LLM utilise plusieurs raisonnements et sélectionne la réponse finale en fonction du plus grand nombre de réponses similaires.

ReAct
Les LLM savent désormais faire appel à des systèmes externes, comme se brancher sur Bing ou appeler un service météo.
Prompt Best Practices
Nous sont données 10 bonnes pratiques de prompt engineering :
- Un exemple vaut 100 instructions
- DARE Determine Appropriate Response
- Rôles, Personas, Public : votre vision
- Objectifs : votre mission
- Portée : si tu ne le sais pas, dis-le-moi !
- Adapter la température au cas d’utilisation
- Utilisez un langage naturel détaillé pour dévoiler une chaîne d’invites
- Structurer les prompts. L’ordre est important. Cédrick recommande de spécifier au prompt quel est l’objectif
- Responsible AI and filters : lorsqu’on enlève les filtres d’un LLM OpenSource on peut avoir de grosses surprises (ex : débrayer la procédure de fabrication d’une bombe).
- Test, Measure, Improve, Repeat : revue par le même LLM ou même d’autres LLM
- Be specific, no open questions. Se limiter (ex: 500 caractères). Sinon le contexte dilue la question
- Review from multiple people
- Detailed algorithms and reasoning problems
Prompt Template
Java permet d’utiliser des templates de prompt. Cédrick compare un template à une boite avec des trous, du publipostage Word, un template Velocity ou encore un template Mustache.
A cet effet, Langchain4j et Spring IA fournissent tous les 2 une classe PromptTemplate
La classe _16_PromptTemplateTest donne un exemple d’utilisation :
@Test
void prompt() {
PromptTemplate promptTemplate = PromptTemplate.from("""
Explain me why a {{profile}} should attend conference {{conference}}.
The conference is on {{current_date}} at {{current_time}} with {{current_date_time}}
""");Map<String, Object> variables = new HashMap<>();
variables.put("profile", "Java Developer");
variables.put("conference", "Devoxx France");Prompt prompt = promptTemplate.apply(variables);
Response<String> response = getLanguageModel("text-bison").generate(prompt);
System.out.println(response.content());
}
protected LanguageModel getLanguageModel(final String modelName) {
return VertexAiLanguageModel.builder()
.project(GCP_PROJECT_ID)
.endpoint(GCP_PROJECT_ENDPOINT)
.location(GCP_PROJECT_LOCATION)
.publisher(GCP_PROJECT_PUBLISHER)
.modelName(modelName)
.build();
}
Limitations des LLM
Un LLM :
- a une date de fraicheur des informations
- n’a pas accès à la base documentaire de l’entreprise
- peut halluciner si il n’est pas bien prompté
- accepte un nombre limité de tokens en entrée
- est lent à répondre
Pour utiliser ses propres connaissances, il est nécessaire d’utiliser un Retrieval-Augmented Generation (RAG)
Vector Search
Pour enrichir les données d’un LLM, il faut les stocker dans une base vectorielle.
Avant cela, il faut les convertir en vecteur. C’est le moment où vous devez faire appel à vos souvenirs de cours de maths.
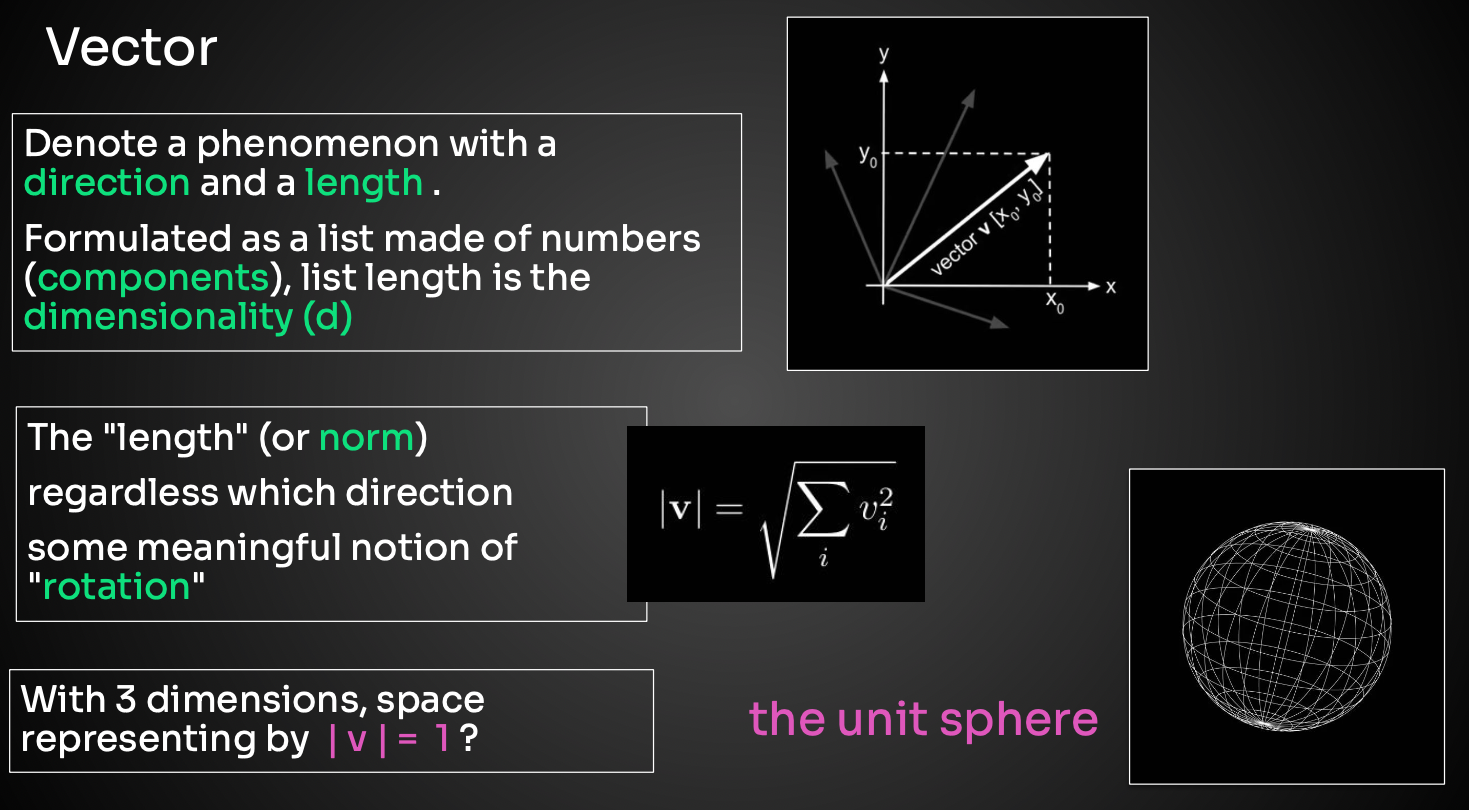
Un vecteur possède une direction et une longueur.
Il est représenté dans un espace à plusieurs dimensions.
En fonction du modèle (vidéo, texte, image), on n’utilise pas la même dimension.
La longueur d’un vecteur s’appelle la norme et se calcule par la racine carrée de la somme des coefficients au carré.
Dans un espace en 3D, la sphère a pour norme |v|=1
Les composantes d’un vecteur sont appelés Embeddings.
Le Prompt est également transformé en vecteur.
On recherche des vecteurs qui sont proches les uns des autres. Cela nécessite de calculer une similarité entre 2 vecteurs.
En maths, il y a plusieurs possibilités de calculer une distance. Un slide est préférable à un long discours :

La plus connue est la distance euclidienne. Elle s’appelle L2 et nécessite beaucoup de calculs.
Cédrick nous fait remarquer que la dimension des vecteurs d’une base vectorielle est multiple de 284.
Les bases vectorielles utilisent plus couramment la distance nommée « Angular distance » ou « cosine similarity »
Chaque base de données implémente sa propre formule. Le plus important consiste à trouver les vecteurs les plus proches. Le plus simple consiste à travailler sur la sphère unité. Je vous laisse apprécier :

Ces calculs amènent beaucoup de zéro après la virgule. En Java, on arrive facilement aux limites de la précision du type double et il est nécessaire d’utiliser des BigDecimal.
La métrique à utiliser dépend du cas d’utilisation.
Le k-Nearest Neighbors (kNN) est une technique fondamentale dans le domaine du Vector Search. Elle permet de trouver les k vecteurs les plus proches d’un vecteur requête (query vector) dans un espace vectoriel. Les présentateurs nous invitent à lire l’article K Nearest Neighbor Classification – Animated Explanation for Beginners
Les calculs de similarité permettant de trouver quels sont les vecteurs les plus proches sont longs, d’où la nécessité d’approximer. L’Approximate Nearest Neighbors(ANN) est un ensemble de techniques qui cherchent à identifier les k voisins les plus proches d’un vecteur requête (query vector) dans un espace vectoriel de haute dimension, mais en introduisant une approximation pour gagner en efficacité.
Le partitionnement des datasets se fait dans un graphe de proximité.
Chaque point du graphe est un vecteur. Le edge est la distance (calculée lorsqu’on sauve le vecteur).
Naturellement, de nombreuses bases vectorielles comme qdrant ou milvus se sont lancées dans le secteur des embeddings. Les bases NoSQL et relationnelles existantes se sont également mises à supporter les vecteurs. On peut citer pgvector sur PostgreSQL, Elasticsearch, Neo4j (qui faisait déjà du graphe) mais encore Apache Cassandra.
Cassandra
Cassandra est une base OSS gouvernée par la fondation Apache.
C’est une base tabulaire, ce qui signifie qu’on ne peut pas faire de jointure lors d’un select et qu’il faut penser au requêtage dès la sauvegarde en dénormalisant les données.
Cassandra ferait une parfaite matrice d’adjacence.
Les nœuds sont distribués et contiennent entre 2 à 4 To de données. L’ajout d’un nœud nécessite de répartir les données. Cassandra scale très bien. Les données sont redondées.
La version 5 de Cassandra introduit le nouveau type Vector :
CREATE TABLE IF NOT EXISTS vsearch.products (
id int PRIMARY KEY,
name TEXT,
description TEXT,
item_vector VECTOR<FLOAT, 5> //5-dimensional embedding
);
Ainsi qu’un nouvel index de stockage attaché appelé StorageAttachedIndex :
CREATE CUSTOM INDEX IF NOT EXISTS ann_index
ON vsearch.products(item_vector)
USING 'StorageAttachedIndex';
ANN est une famille d’algorithme de recherche approximative.
L’opérateur ANN OF permet d’effectuer efficacement des recherches ANN sur leurs données lors d’une recherche CQL :
SELECT * FROM vsearch.products
ORDER BY item_vector ANN OF [0.15, 0.1, 0.1, 0.35, 0.55]
LIMIT 1;
Le site ann-benchmarks.com compare les performances brutes des algorithmes de recherche approximative des plus proches voisins.
Aujourd’hui, presque toutes les bases utilisent la technique du HNSW (pour Hierarchical Navigable Small World) avec des Vector Index stockés dans plusieurs couches : Lucene (Elastic, Solr, OpenSearch, MongoDB), Weaviate, Qdrant, PGVector.
Lucene avait déjà implémenté l’algo HNSW. Cassandra l’a utilisé dans Cassandra. Un problème majeur à son utilisation est que Java utilise beaucoup de mémoire, notamment lorsque dataset et sharding augmentent. Les ingénieurs de Cassandra ont donc planché sur une autre solution.
Dans un premier temps, Cassandra a testé l’algo DiskANN (papier implémenté par Microsoft en C). lls l’ont recodé en Java et l’ont baptisé jVector. Le projet jVector utilise Java 21 et la nouvelle API Vector du projet Panama permettant d’exploiter les instructions SIMD.
Vanama stocke le graphe sur un seul layer et crée plus de liens que nécessaires. Les distances sont précalculées lors de l’indexation. En mémoire, on ne monte plus les vecteurs en entier, mais des données plus petites, les centroids, et ceci par quantification. Au lieu de travailler avec un Vecteur, on utilise des centroids.
Le plus souvent, dans des cas métiers, une recherche par vecteur n’est pas suffisante. Il est nécessaire d’exploiter des métadonnées : date d’indexation, auteur, prise en compte des habilitations …
Lecture conseillé : 5 Hard Problems in Vector Search, and How Cassandra Solves Them
Pour choisir sa base de données vectorielles, Cédrick conseille aux architectes d’utiliser le comparateur Vector DB Comparison
Repartons dans notre IDE préféré pour montrer l’utilisation de Langchain4j et de Cassandra.
Cédrick utilise la nouvelle classe d’abstraction : `EmbeddingModel
On lui donne du texte et il sort un vecteur.
Code extrait de la classe _51_EmbeddingModel:
@Test
void testEmbeddingModel() {
Response<Embedding> embedding = getEmbeddingModelGecko().embed("Hello, World!");
log.info("Dimension: {}", embedding.content().dimension());
log.info("Vector: {}", embedding.content().vectorAsList());
}protected EmbeddingModel getEmbeddingModelGecko() {
return VertexAiEmbeddingModel.builder()
.project(GCP_PROJECT_ID)
.endpoint(GCP_PROJECT_ENDPOINT)
.location(GCP_PROJECT_LOCATION)
.publisher(GCP_PROJECT_PUBLISHER)
.modelName("textembedding-gecko@001")
.build();
}
La modélisation des données sous Cassandra est complexe. Aussi, pour faciliter la modélisation, l’usage de Cassio est recommandé.
S’en suit la démo _54_CassandraVectorStore montrant l’usage de tags pour filtrer des requêtes. La classe EmbeddingStore est mise à l’honneur.
@Test
void langchain4jEmbeddingStore() {
// I have to create a EmbeddingModel
EmbeddingModel embeddingModel = getEmbeddingModelGecko();// Embed the question
Embedding questionEmbedding = embeddingModel
.embed("We struggle all our life for nothing")
.content();// We need the store
EmbeddingStore<TextSegment> embeddingStore = new CassandraCassioEmbeddingStore(
getCassandraSession(), TABLE_NAME, EMBEDDING_DIMENSION);// Query (1)
log.info("Querying the store");
embeddingStore
.findRelevant(questionEmbedding, 3, 0.8d)
.stream().map(r -> r.embedded().text())
.forEach(System.out::println);// Query with a filter(2)
log.info("Querying with filter");
embeddingStore.search(EmbeddingSearchRequest.builder()
.queryEmbedding(questionEmbedding)
.filter(metadataKey("author").isEqualTo("nietzsche"))
.maxResults(3).minScore(0.8d).build())
.matches()
.stream().map(r -> r.embedded().text())
.forEach(System.out::println);}
En production, il manque encore des fonctionnalités pour, par exemple, rafraichir les données de la base vectorielle tout en optimisant le cout.
A ce jour, toutes les bases de données vectorielles ne savent pas encore implémenter tous les filtres de Langchain4j. La distribution Cloud de Cassandra nommée AstraDB ajoute les filtres manquants.
Retrieval Augmented Generation (RAG)
Le processus Retrieval Augmented Generation (RAG) consiste à optimiser le résultat d’un LLM. 2 types de RAG existent : naive et advanced.
Un vecteur de dimension 1000 ne peut pas stocker l’intégralité d’un document. On découpe donc ce document en morceau (chunk). Il existe plusieurs techniques pour faire du chunking.
Des préprocesseurs commencent par lire les documents (avec par exemple Apache Tika et Apache PDFBox), retirent les balises, normalisent l’encodage (UTF-8). Ceci pour ne conserver que le texte brut. Chaque extension de fichier (ex : markdown) demande un parseur.
Sur OpenAI, on peut mettre entre 256 et 512 tokens par vecteur de dimension 1536.
Pour garder le contexte, les segments doivent se superposer.

Astuce pour sauvegarder le segment : ajouter un hash dans les métadonnées du document, ce qui évite de le réindexer pour rien.
Nouvelle démo basée sur le test _62_NaiveRag_RetrievalTest et montrant l’usage des interfaces ContentRetriever et Assistant de langchain4j :
@Test
void shouldRetrieveContent2() {ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(new AstraDbEmbeddingStore(getCollectionRAG()))
.embeddingModel(getEmbeddingModelGecko())
.maxResults(2)
.minScore(0.5)
.build();// configuring it to use the components we've created above.
Assistant ai = AiServices.builder(Assistant.class)
.contentRetriever(contentRetriever)
.chatLanguageModel(getChatLanguageModelChatBison())
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.build();String response = ai.answer("Who is Johnny?");
System.out.println(response);
}
Les advanced RAG consistent à mettre à disposition un query router utile, par exemple, pour séparer les requêtes des tenants, exploiter les niveaux de confidentialité des documents …
Lors de longues discussions, on peut atteindre les limites du LLM. Il est alors possible de faire un résumer de l’historique de la conversation. Usage des Query Transformer et de la classe CompressingQueryTransformer de langchain4j.
Lorsqu’il y’a plusieurs résultats, il faut les agréger via des Query Aggregator. Les algorithmes de reranking peuvent utiliser d’autres algorithmes. La star du reranking s’appelle Cohere.
La classe de test _66_AdvancedRag_QueryReranking en donne un exemple d’utilisation :
@Test
void shouldRerankResult() {// Re Ranking
ScoringModel scoringModel = CohereScoringModel.withApiKey(System.getenv("COHERE_API_KEY"));ContentAggregator contentAggregator = ReRankingContentAggregator.builder()
.scoringModel(scoringModel)
.minScore(0.8)
.build();RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.contentRetriever(createRetriever("/johnny.txt"))
.contentAggregator(contentAggregator)
.build();Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(getChatLanguageModelChatBison())
.retrievalAugmentor(retrievalAugmentor)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.build();System.out.println( assistant.answer("Tell me 10 things about Johnny"));
}
A noter l’utilisation des interfaces RetrievalAugmentor et ScoringModel de langchain4j.
Functions calling & Semantic Search
Ce talk se termine par une démonstration de la notion de Tool de langchain4j.
Pour récupérer la météo à Paris, Gemini sait qu’il existe une API permettant de récupérer le temps.
En java, on annote une méthode avec @Tool, ce qui permet au LLM d’appeler ce tool lorsqu’on lui pose la question d’additionner deux nombres.
Extrait de la classe de test _71_CallFunctionTest:
static ChatLanguageModel model= VertexAiGeminiChatModel.builder()
.project(GCP_PROJECT_ID)
.location(GCP_PROJECT_LOCATION)
.modelName("gemini-pro")
.build();static class Calculator {
@Tool("Adds two given numbers")
double add(double a, double b) {
System.out.printf("Called add(%s, %s)%n", a, b);
return a + b;
}
}interface Assistant {
String chat(String userMessage);
}@Test
void testFunctionCalling1() {Calculator calculator = new Calculator();Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.tools(calculator)
.build();String answer = assistant.chat("How much is 754 + 926?");
System.out.println(answer);
}