
Conférence : Devoxx France 2024
Date : 19 avril 2024
Speakers : Lucian Precup (Adelean)
Format : Tools in action (30 mn)
Lors de cette 12ième édition de Devoxx France, j’ai eu l’agréable surprise de voir 4 anciens collègues animer un talk : Guillaume Darmont sur Java Flight Recorder et Java Mission Control, Florian Boulay sur emacs, Stéphane Landelle sur Netty et Lucian Precup sur Lucene. Avec ce dernier, nous avons mis en œuvre Elasticsearch sur une application métier au cœur du SI d’une grande entreprise. C’était il y’a plus de 10 ans. Expert en moteur de recherche, je me souviens encore Lucian m’expliquer ce qu’est un index inversé.

Lucian commence par sonder son public. Fait notable, dans l’assistance, personne n’utilise un moteur de recherche qui ne serait pas basé sur Apache Lucene, technologie à la base de milliers de moteur de recherche et dont Lucian va nous retracer l’histoire.
Créé en 2001, Apache Lucene a aujourd’hui plus de 22 ans. C’est un projet Open Source de la fondation Apache toujours maintenu et même très actif. Chose assez rare dans le monde OSS qui voit passer de nombreux projets.
Développé en Java, Lucian nous explique les raisons de la longévité de Lucene :
- Fédère une communauté de passionnés
- Permet la réalisation de nombreux cas d’utilisation métiers
Sur X / Twitter, Lucian suit les contributeurs de Lucene depuis 2010 et voit régulièrement annoncer des améliorations très impressionnantes. 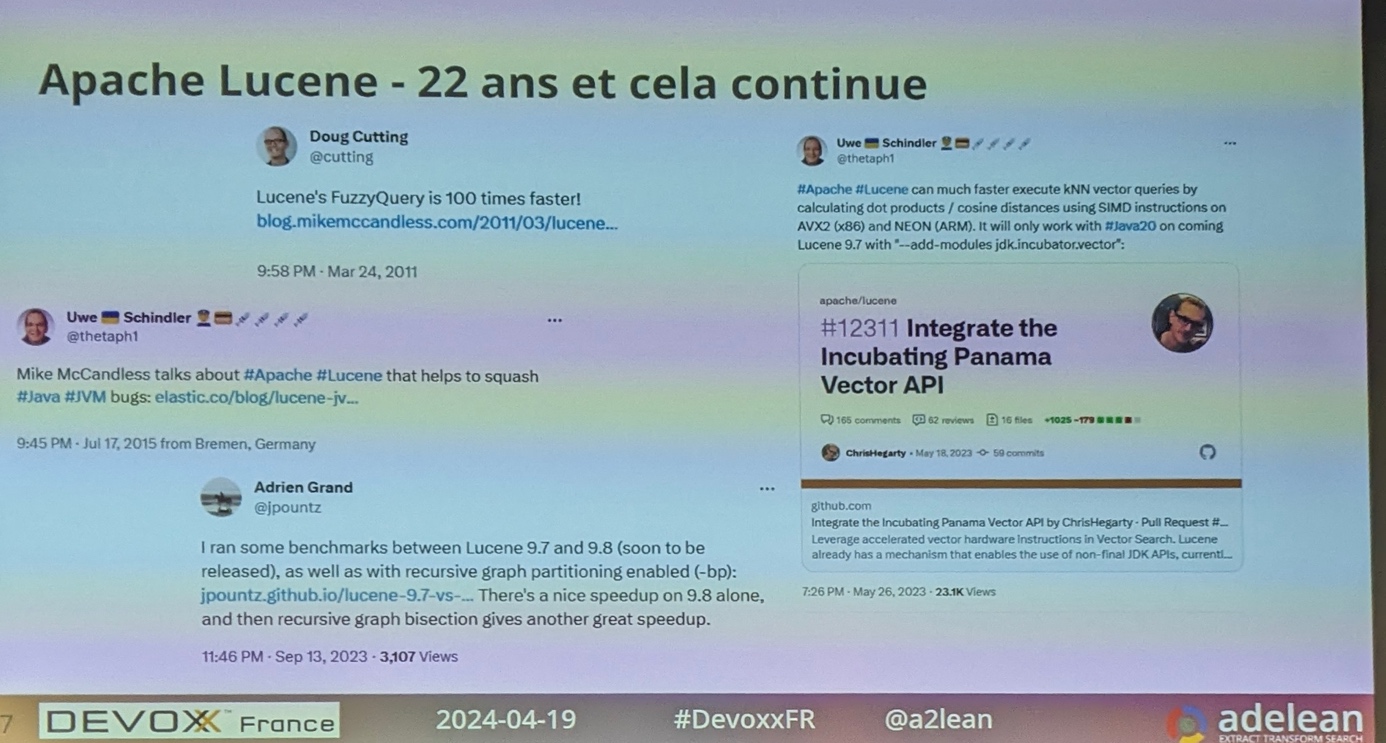
Pendant longtemps, le projet Lucene fut le projet OSS qui a découvert le plus de bug dans la JVM.
La dernière amélioration notable de Lucene consiste à bénéficier de l’API Vector pour améliorer les performances en utilisant les instructions SIMD des processeurs.
Lucian assiste régulièrement à la conférence mondiale sur le search : la Berlin Buzzworlds
Chaque année, Uwe Schindler ou l’un de ses collègues annonce les nouveautés de Lucene
En 2031 Lucian parie qu’il y’a aura encore un talk sur Apache Lucene. Rendez-vous tenu !
Lucene a permis de motoriser :
- Apache Nutch : a posé les fondations de Hadoop
- Apache Solr : serveur de recherche entreprise
- Elasticsearch : moteur de recherche
- MongoDB Atlas Search : moteur de recherche d’entreprise cloud native basée sur MongoDB
- OpenSearch : fork d’Elasticsearch 7 créé par Amazon
- Les solutions Adelean a2 et all.site
Lucien continue par présenter les notions fondamentales de Lucene.
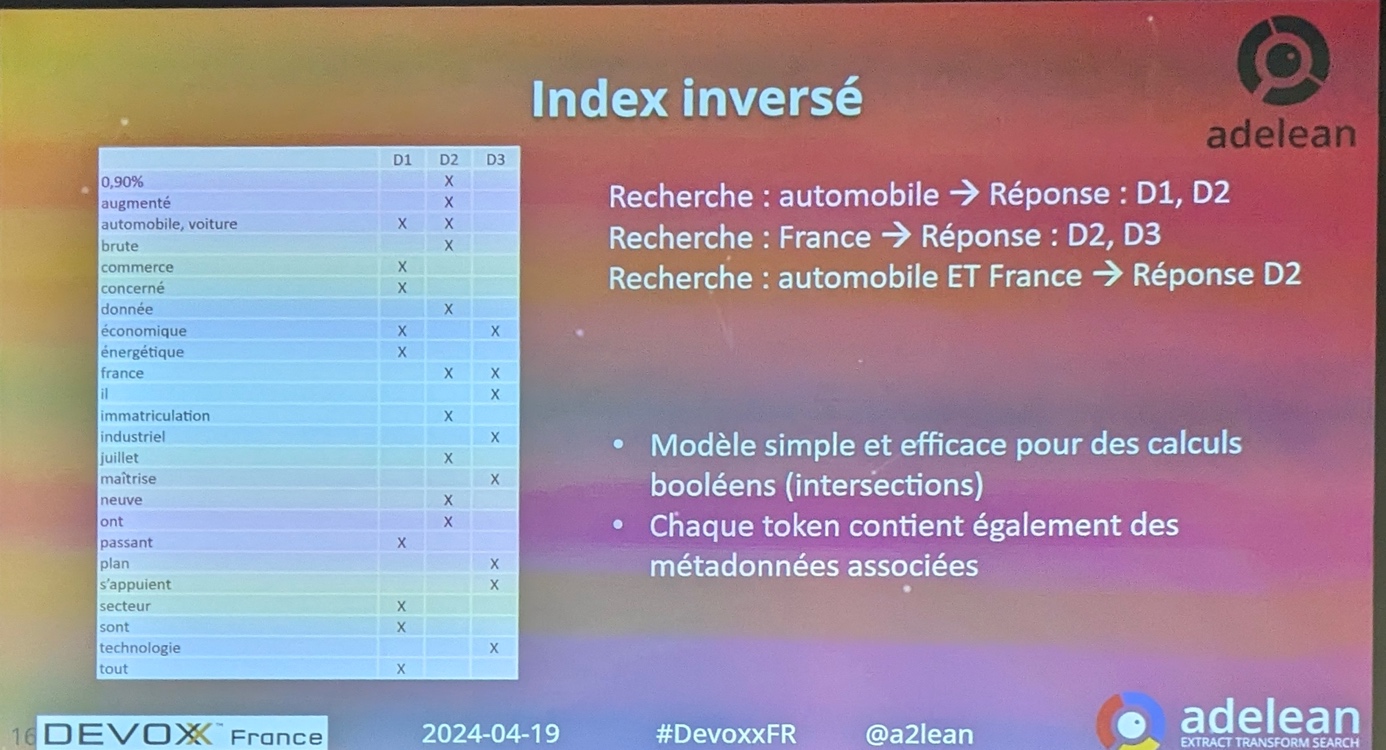
Index inversé
L’index inversé est le concept fondateur de Lucene.
Lucian prend l’exemple de 3 documents à indexer :
- D1 : « tous les secteurs économiques, du commerce au secteur automobile en passant âr me secteur énergétique sont concernés. »
- D2 « Les immatriculations de voitures neuves en France ont augmenté de 0,9% en données brutes en juillet. »
- D3 « Ils s’appuient sur des technologies que la France maitrise sur le plan industriel et économique. »
Ces phrases sont tokenisées en termes puis stockées dans un index dit inversés. Cet index ressemble à une Map ayant pour clé les termes et pour valeur l’ensemble des éléments référençant le token.
Des raffinements sont possibles : suppression des majuscules, stemming (gestion du singulier et du pluriel), stopwords (comme les articles) …
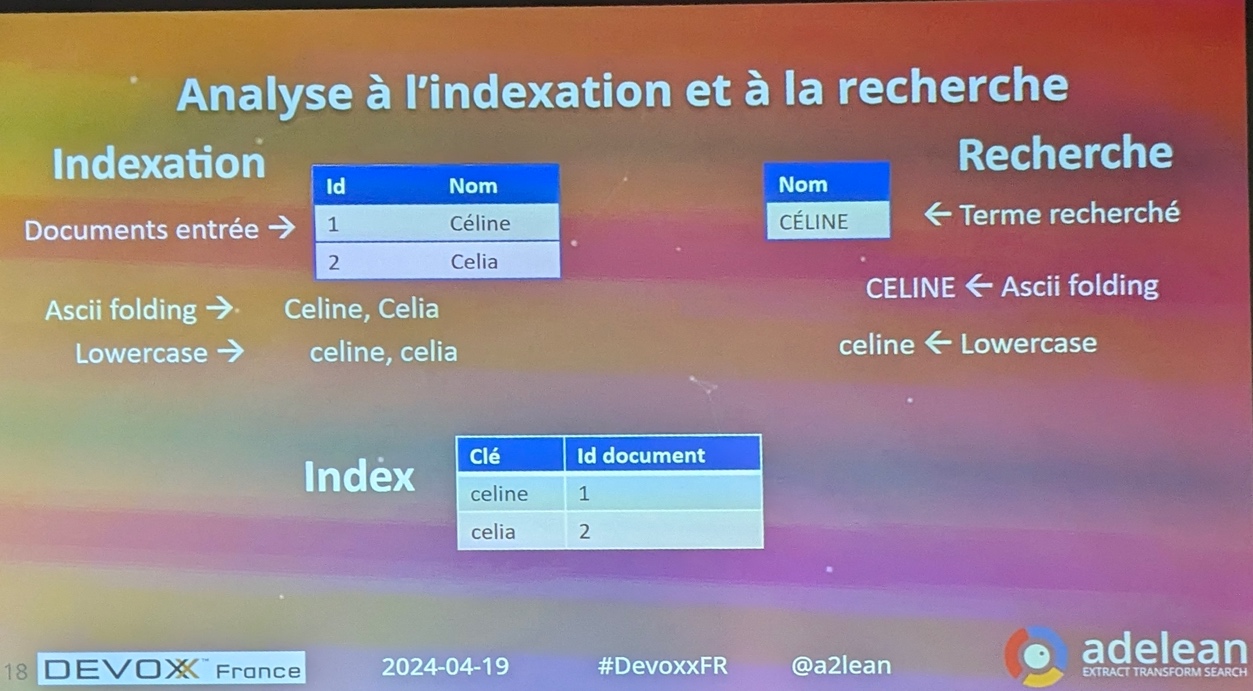
Un index inversé est extrêmement performant, les recherches booléennes très rapides.
Cette toute première version de Lucene serait un bon exercice pour un candidat, un étudiant ou même Chat GPT
Lucene a continué d’évoluer pour supporter l’auto-complétion avec nGram. Un index est spécialement créé avec toutes les étapes d’une auto-complétion (cet index pourrait être gros et il est donc compressé).
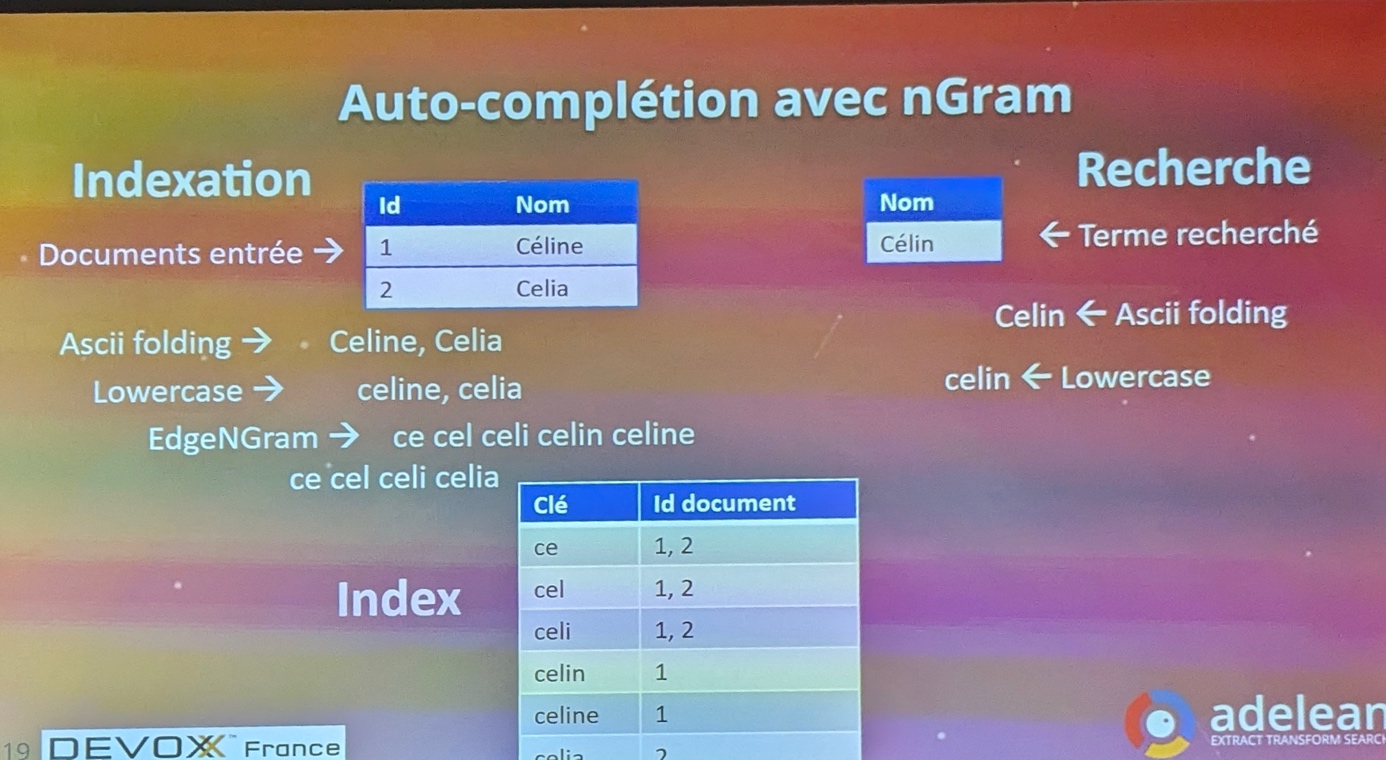
Chose amusante, les premières versions de Lucene ne supportaient pas les nombres.
Il fallait utiliser des pseudo nombres et utiliser du padding et comparer des chaines de caractère. Exemple : « 00001 » < « 00004 »
Cette fonctionnalité a été ajoutée suite aux besoins de sites e-commerces.
S’ensuit de nouvelles fonctionnalités comme les facettes, les facettes imbriquées, les facettes avec intervalles …
Lucene 4 : introduction un stockage en colonne avec les DocValues
Cela permet d’excellentes performances pour les tris ou bien encore les agrégations. Cas d’utilisation très populaires dans les outils de monitoring et d’observabilité.
Lucene sait donc stocker les données en colonne comme le fait la base NoSQL Cassandra.
Vient ensuite le besoin de faire des recherches sur des données spatiales
Ce sujet est complexe si on veut être rapide. Nécessité de structures particulières : Type Geo Point, Geo Shape …

Lucene est devenue une base de données spatiales, peut être l’une des plus performantes d’après Lucian ?
Ces dernières années, l’IA Générative est arrivée.
Cela a poussé Lucene à introduire de la recherche vectorielle. La vectorisation permet de représenter des documents sous forme de nombres dans un espace mathématique, ce qui facilite leur analyse et leur traitement par des algorithmes. Chaque élément dans ce vecteur représente une caractéristique du document.
Lucene permet de classer des documents (textes ou images) dans une base vectorielle. 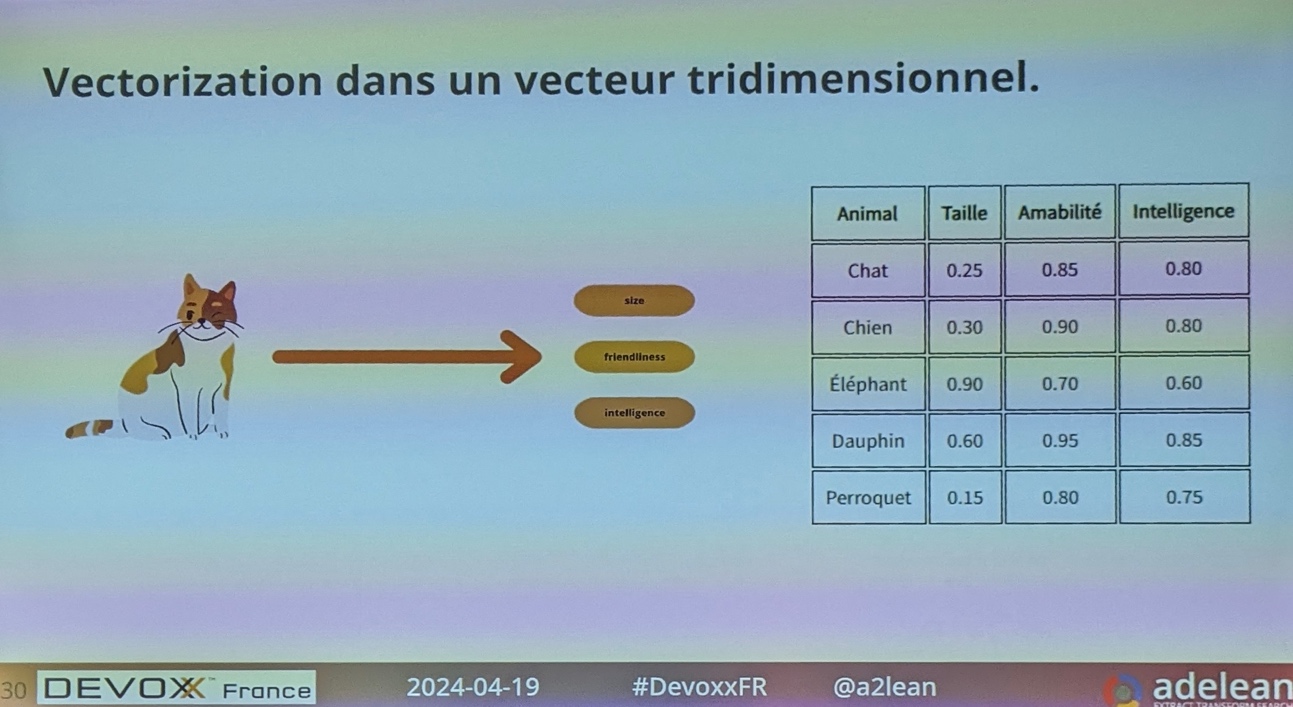
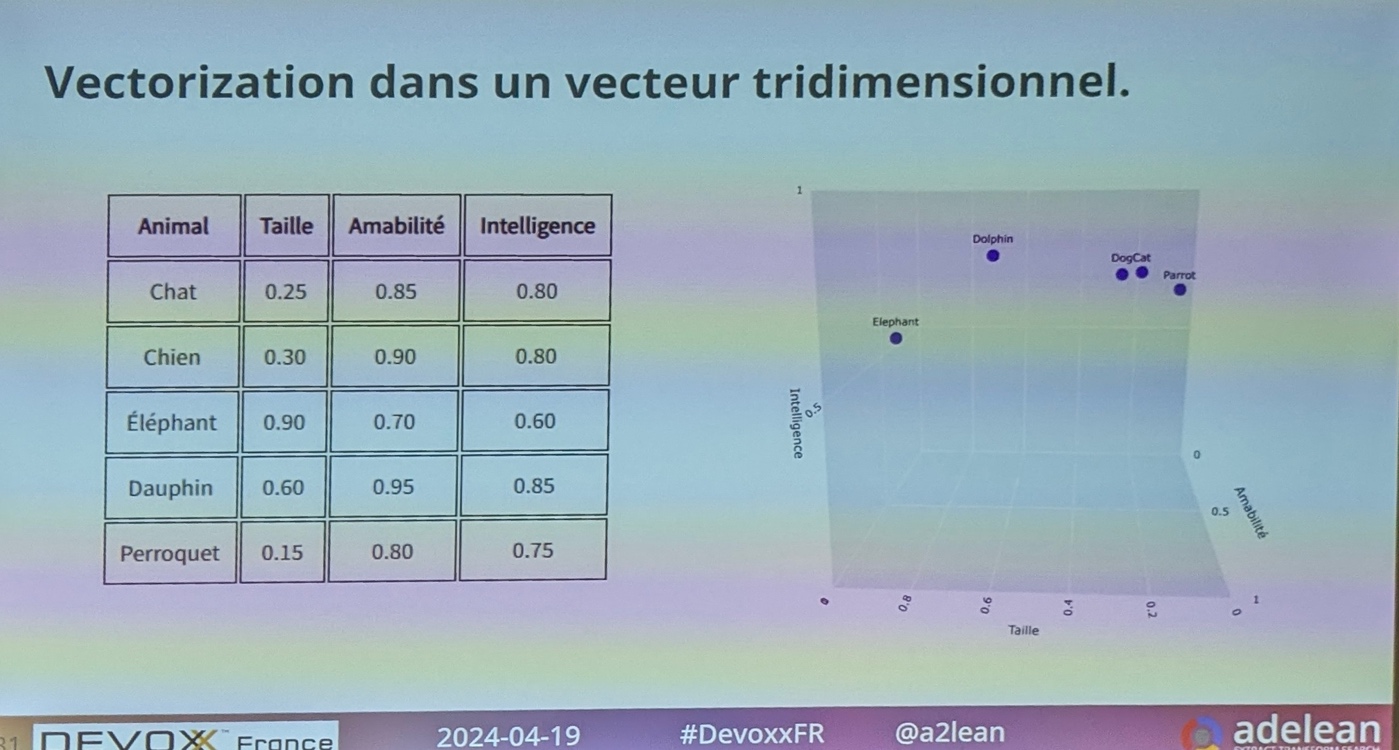
Lucene supporte plusieurs centaines de dimensions. Le Vector Search est désormais possible grâce à la représentation vectorielle d’un texte. Les mots « clémentine » et « mandarine » peuvent alors être positionnés au même endroit (plus besoin d’utiliser les synonymes)
On retrouve 2 types de vecteur : creux et dense
Les vecteurs creux sont moins couteux.
Le vecteur va être ajouté au document transformé, et un algorithme de similarité va être utilisé pour retrouver le document le plus pertinent.
Exemple de « Term expansion » :
Retrieval Augmented Generation (RAG)
Le RAG est la réponse de Lucene à ChatGPT. Lucian rappelle que ChatGPT n’a pas de connaissance en temps réel. Par exemple, la connaissance de Chat GPT 3.5 s’arrête en janvier 2022 ; il ne connait pas Langchain4j qui est trop récent.
Ces LLM sont programmés pour générer des mots, d’où les hallucinations. Ils se forcent à répondre
Une solution consiste à générer du texte augmenté par récupération.
Le RAG mélange moteur de recherche et LLM.
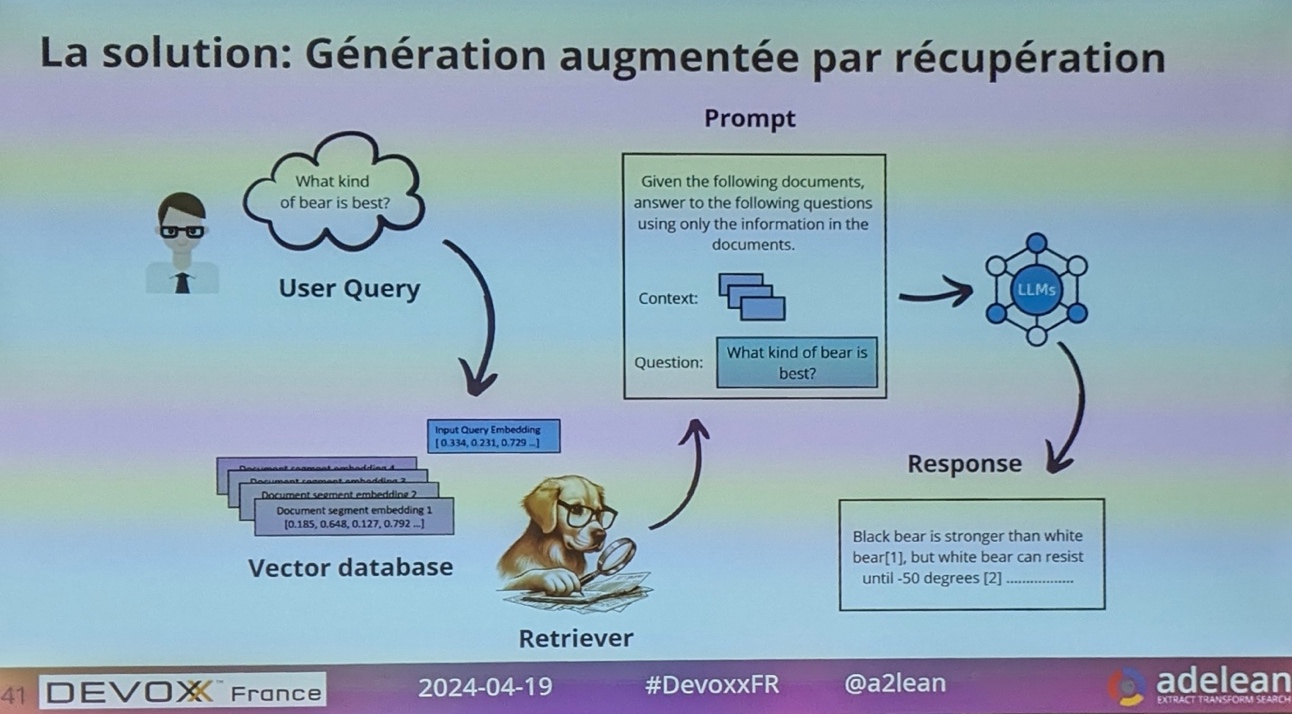
Avec les User Query, on n’utilise plus du fulltext search.
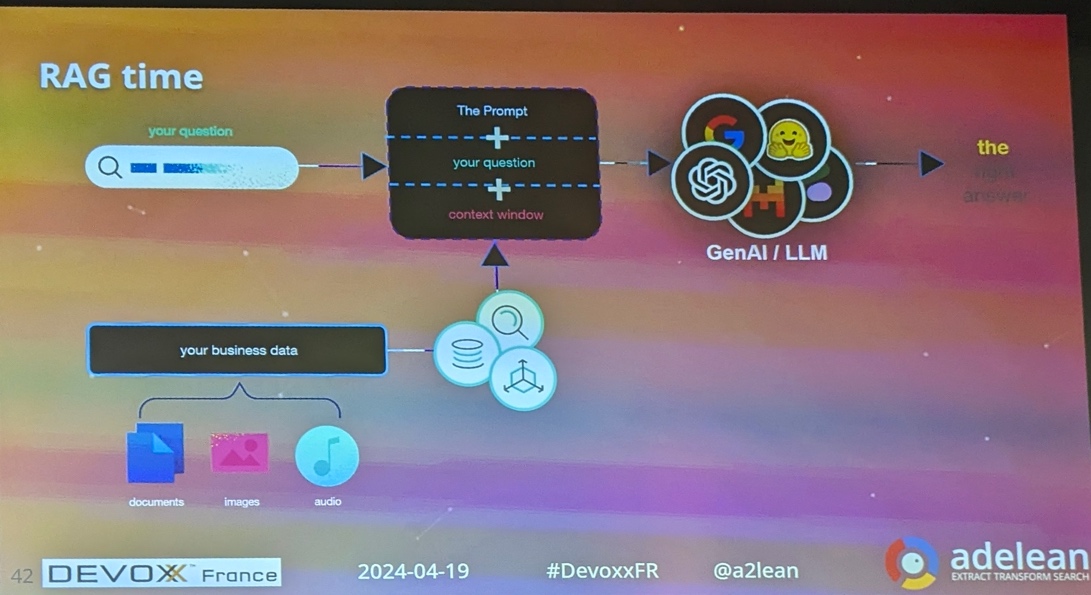
Atelier RAG time
Le Hands-On Lab RAGtime : Discuter avec vos propres données était consacré au buzzword de 2024.
Ressources
Pour terminer sur Lucene, voici quelques ressources conseillées par Lucian :
- Le livre AI Powered Search, Trey Grainger, Doug Turnbull, Max Irwin (Manning)
- Articles du blog de la société Adelean
- Diving into NLP with the Elastic Stack, Pietro Mele
- From voice to text, the power of the Open Source ecosystem – return on the OSXP conference, Lucian Precup
- Understanding the differences between sparse and dense semantic vectors, Pietro Mele
- NLP in OpenSearch, Pietro Mele