
« Près de 2 ans passés chez un client en tant que référent technique d’un middle de recherche basé sur le moteur de recherche Elasticsearch, il me paraît aujourd’hui opportun de vous faire part des différentes problématiques rencontrées au cours des développements et de son exploitation. »
En 2 versions majeures et une montée de version d’Elasticsearch, les problématiques abordées ont été nombreuses : occupation mémoire, ré-indexation sans interruption de service, Split Brain, IDF et partitionnement. Prêts pour ce retour d’expérience ? »
RÉINDEXATION SANS INTERRUPTION DE SERVICE
Dans notre application, l’index Elasticsearch utilisé pour la recherche est construit à l’aide d’un batch Java. Les données indexées proviennent d’une base de données relationnelle. Une fois construit, l’index est mis à jour en temps réel par un système sophistiqué de notifications.
Malgré ce dispositif, il est parfois nécessaire ou préférable de reconstruire totalement l’index. Voici quelques exemples : exécution de scripts SQL de rattrapage sur la base de données source, chargement en masse de nouvelles données, pertes de notification, évolution du mapping de l’index…
En fonction de la sollicitation de la base de données source et du cluster Elasticsearch, l’alimentation d’un index de plusieurs dizaines de millions de documents peut prendre jusqu’à 2h. Or, les services de recherche ont une haute disponibilité avec un SLA de 24/7. Hors de question de les interrompre pendant cette plage horaire de maintenance.
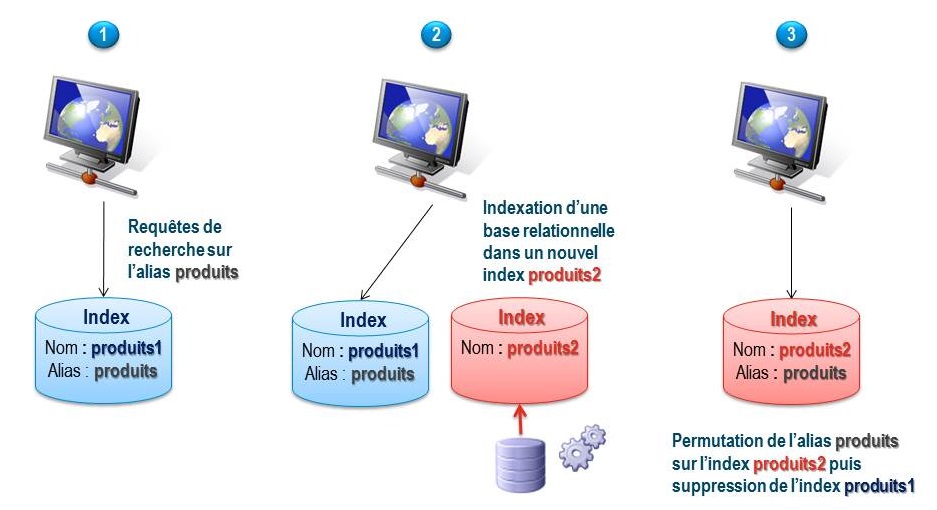
La solution à ce problème est illustrée sur le schéma suivant :
Voici quelques précisions concernant chacune de ces 3 étapes :
- Au lieu d’interroger un index directement à partir de son nom physique (ici produits1), l’application cliente d’Elasticsearch (ex : HTML ou Java) utilise un nom logique (produits) matérialisé dans Elasticsearch par un alias.
- Le batch commence par déterminer quel est le nom de l’index qu’il doit construire. Il regarde à quel index est lié l’alias produits. Dans l’exemple ci-dessus, il s’agit de produits1. Le batch en déduit qu’il doit construire un nouvel index produits2.
- A la fin de l’indexation, le batch utilise l’API d’Elasticsearch pour faire pointer l’alias clients vers le nouvel index clients2. L’index clients1 est supprimé. Ce changement est transparent pour l’application cliente.
Voici le code Java permettant de changer l’alias en une seule requête Elasticsearch :
// Bascule l'alias de l'ancien index vers le nouvel index
IndicesAliasesRequestBuilder aliasesReqBuilder = esClient.admin().indices().prepareAliases();
aliasesReqBuilder.addAliasAction(new AliasAction(Type.ADD, "produits2", "produits"));
aliasesReqBuilder.addAliasAction(new AliasAction(Type.REMOVE, "produits1", "produits"));
aliasesReqBuilder.execute().actionGet();Pour aller plus loin, l’article Changing mapping with zero downtime de Clinton Gormley explique quelles sont les opérations nécessitant une reconstruction de l’index. L’auteur confirme que l’utilisation d’un alias est la solution à privilégier pour garantir la haute disponibilité d’une application.
OUTOFMEMORYERROR
Au cours des développements et des tests de montée en charge du middle de recherche, nous sommes tombés à plusieurs reprises sur la tant redoutée OutOfMemoryError. A chaque fois, les raisons différaient. Etudions en quelques-unes.
TRI DES RÉSULTATS

Une attente récurrente des utilisateurs est de pouvoir trier leurs résultats en fonction de critères prédéfinis. Or, nativement, les résultats sont ordonnés en fonction d’un score calculé par chaque instance Lucene et agrégé par Elasticsearch. En fonction des règles de mapping et de recherche définies par les développeurs, les résultats les plus pertinents remontent en tête.
Pour ordonner les résultats différemment, Elasticsearch propose des fonctionnalités de tri. Ces fonctionnalités étaient disponibles dans la version 0.19.2 que nous utilisions. Nous nous sommes donc naturellement appuyés dessus pour implémenter des tris ressemblants aux cas présentés dans la capture d’écran ci-jointe.
Mis en place sans grande difficulté, la recette de l’application a confirmé que leur mise en œuvre satisfaisait les attentes du métier. Malheureusement, nos tests de charge ont mis en évidence des problèmes de mémoire. Après quelques minutes, les logs d’Elasticsearch remontaient des OutOfMemoryError et les nœuds incriminés passaient en mode dégradé.
En désactivant les ordres de tris des scénarios de recherche, les tests de charge passaient haut la main.
Après investigation, nous nous sommes rendu compte qu’Elasticsearch met en cache toutes les valeurs des champs triés. La première fois qu’un tri est demandé sur un champ, Elasticsearch construit son cache et le temps de réponse en est fortement impacté. La mise en place de warmup est possible pour éviter ce désagrément au premier utilisateur.
Les APIs d’administration et de supervision d’Elasticsearch permettent de consulter la taille du cachedes tris. A partir de la volumétrie de production, nous avons pu mesurer qu’il nous faudrait 2,4 Go de mémoire rien que pour activer l’ensemble des tris. Les 2 Go de Xmx alloués par l’exploitation ne suffisaient donc pas.
Les APIs de la version 0.19.2 d’Elasticsearch ne permettent pas de voir la répartition de la mémoire par champ. Nous avons tout de même pu les mesurer à coup d’arrêt / relance / tri unitaire. Pour vous donner une idée, mettre en cache les codes postaux des adresses demandait 94 Mo. Or, le nombre de codes postaux est fini. Tous uniques, la taille demandée par des identifiants n’en est que décuplée.
Elasticsearch étant installé sur une JVM 32 bits et un Linux, la limite des 3 Go de Xmx et les contraintes projets ont dû nous contraindre à désactiver les tris dans la V1 de notre application.
Nous n’avons réactivé les tris que récemment, profitant d’une montée de version d’Elasticsearch, et plus précisément la 0.90.5. Entre les 2 versions, l’occupation mémoire des données dans le cache a été grandement optimisée. A titre d’exemple, avec le même nombre de code postaux, le cache est passé de 94 Mo à 28 Mo. Suite à cette montée de version et à quelques améliorations apportées dans le mapping de notre index, la taille du cache a été calculée à 773 Mo (à comparer aux 2,4 Go précédents). Une fois la JVM configurée pour utiliser 3 Go de Xmx, les tests de charge ont été concluants.
Exemple d’utilisation de l’API stats demandant la taille des caches de l’ensemble des nœuds du cluster :
Requête : GET http://localhost:9200/_nodes/stats/indices/fielddata/*?pretty
Réponse :
"nodes" : {
"BZa34kwxRPqsxumXHIvCXa" : {
"timestamp" : 1385115057137,
"name" : "Noeud2",
"transport_address" : "inet[/172.30.31.12:9300]",
"hostname" : "localhost",
"attributes" : {
"max_local_storage_nodes" : "3",
"zone" : "zoneB"
},
"indices" : {
"fielddata" : {
"memory_size" : "773.2mb",
"memory_size_in_bytes" : 810758963,
"evictions" : 0,
"fields" : {
"codepostal" : {
"memory_size" : "28.1mb",
"memory_size_in_bytes" : 29464985
},
"tarif" : {
"memory_size" : "65.9mb",
"memory_size_in_bytes" : 69101158
},
...LUCENE ET LES JVM 32 BITS
Au cours de la migration du middle de recherche de la version 0.19.2 d’Elasticsearch à une version 0.90.x, nous sommes tombés de manière inopinée sur un OutOfMemoryError remonté par l’API Java Elasticserarch de recherche. Comme le montre la pile d’appel ci-dessous, le message d’erreur référence le bug Lucene LUCENE-1566 Large Lucene index can hit false OOM due to Sun JRE issue :
[2013-11-25 21:26:14,080][DEBUG][action.search.type] [elasticSeachNode] [client12][0], node[mflXc6jJS9CaJiYaCrKe2g], [P], s[STARTED]: Failed to execute [org.elasticsearch.action.search.SearchRequest@1ea6e24]java.lang.OutOfMemoryError: OutOfMemoryError likely caused by the Sun VM Bug described in https://issues.apache.org/jira/browse/LUCENE-1566; try calling FSDirectory.setReadChunkSize with a value smaller than the current chunk size (104857600) at org.apache.lucene.store.NIOFSDirectory$NIOFSIndexInput.readInternal(NIOFSDirectory.java:184) at org.apache.lucene.store.BufferedIndexInput.readBytes(BufferedIndexInput.java:158) ... at org.elasticsearch.search.query.QueryPhase.execute(QueryPhase.java:127) ...
Le ticket Lucene référence à son tour un bug de la JVM Hotspot : JDK-6478546 : FileInputStream.read() throws OutOfMemoryError when there is plenty available. Sur des JVM 32 bits, la lecture de fichiers de plusieurs centaines de mega-octets provoque à tort des OutOfMemoryError sur les JVM ayant une heap conséquence.
Bien que ce bug soit marqué comme corrigé depuis la version 2.9 de Lucene, tous les critères de ce bug étaient réunis :
- JVM 32 bits Java 6
- Sur le disque, la taille des index Lucene occupe entre quelques méga-octets et 2 Go
- Heap de 2 Go
Pour résoudre ce problème, nous sommes simplement passés à une JVM Java 7 64 bits. Ce changement a été rendu possible grâce à une demande réalisée un an plus tôt auprès de l’équipe d’exploitation, ceci en prévision d’une éventuelle augmentation de mémoire au-delà des 3 Go de Heap, le maximum sous Linux des JVM 32 bits.
Batch d’indexation en erreur
Lors de la montée de version d’Elasticsearch de la version 0.90.2 à 0.90.3, le batch d’indexation est tombé en OutOfMemoryError. Configuré avec 512 mo de Xmx, le batch n’avait jusque-là jamais posé de problème particulier.
Multi-threadé, le batch a été paramétré pour traiter simultanément 5000 documents par thread. L’empreinte mémoire des documents indexés est relativement petite, de l’ordre de 1 ou 2 ko.
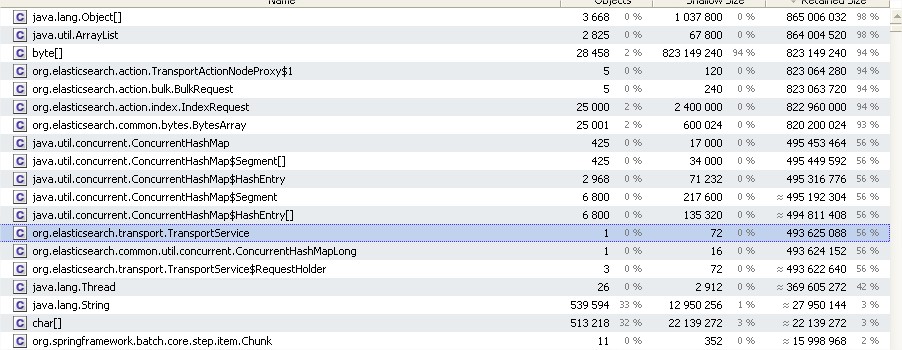
Entre les 2 versions, notre profiler Java nous a montré qu’à volumétrie égale (25 000 requêtes), l’empreinte mémoire des instances de la classe IndexRequest était passée de 29 Mo à 823 Mo :
Ayant identifié le problème, j’ai remonté le bug 3624 dans le GitHub d’Elasticsearch. Dans l’heure qui a suivi, Shay Banon, le créateur d’Elasticsearch en personne, a pris en main le sujet. Il a identifié que lataille minimale du buffer des requêtes était passé de 1 Ko à 32 Ko entre les 2 versions. Le lendemain, il publiait un patch faisant repasser le buffer à 2 Ko. Dix jours plus tard, le patch était disponible dans la version 0.90.4 d’Elasticsearch. Entre temps, nous avons utilisé un contournement indiqué par Shay permettant de fixer manuellement la taille du buffer.
SPLIT BRAIN
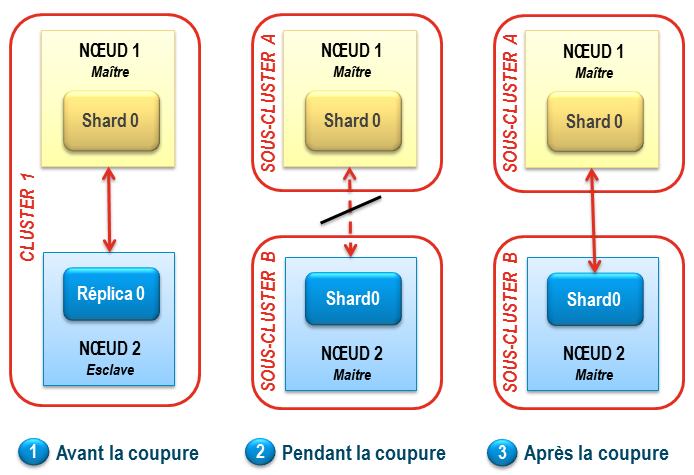
Durant les premiers mois d’exploitation de notre cluster Elasticsearch, nous sommes tombés sur le phénomène du Split Brain.
Techniquement, notre cluster Elasticsearch comporte 2 nœuds. Chaque nœud est réparti sur site géographique distinct. Chaque nœud héberge un seul index Elasticsearch formé d’un shard et d’un réplica.
Le Split Brain Elasticsearh est survenue après une coupure réseau d’1 mn 30. Le schéma suivant montre l’état du cluster avant, pendant et après la coupure :
- Pour fonctionner, un cluster Elasticsearch nécessite d’avoir un nœud maître. Le nœud 1 joue ce rôle. Il héberge la partition primaire (shard 0). Le nœud 2 est esclave et contient le réplica de la partition du nœud 1. Le réplica est une copie de la partition primaire et peut faire office de backup en cas de défaillance du nœud 1.
- Une coupure réseau intervient entre les 2 nœuds. Lorsqu’il essaie de communiquer avec son maître, le nœud 2 se prend une ConnectTransportException. A 3 reprises, toutes les 30 secondes, le nœud 2 essaie de se reconnecter au cluster. En vain. Possédant un réplica complet de l’index, sans nœud voisin, le nœud 2 va alors s’autoproclamer maître. Deux « sous-clusters » existent sur le réseau, chacun étant capable de répondre à des requêtes de recherche et d’indexation.
- Une fois le réseau rétabli, les 2 nœuds ne se réunissent pas en un seul et unique cluster comme on pourrait s’y attendre. Deux clusters indépendants coexistent. C’est ce que l’on appelle le Split Brain. Cette situation entraîne une divergence progressive des données indexées sur chacun des 2 sous-clusters, tantôt les requêtes d’indexation arrivant sur le nœud 1, tant sur le nœud 2.
Ce problème est difficile à mettre en évidence car toutes les requêtes de recherche comme d’indexation répondent. Nous nous en sommes aperçus par hasard à quelques jours d’une nouvelle mise en production du middle de recherche, en vérifiant les logs Elasticsearch. Après redémarrage d’un des nœuds, une réindexation totale des données a été réalisée. En attendant de trouver une solution plus pérenne, le dossier de supervision a été complété afin de nous alerter en cas de récidive.
La solution à ce problème est connue et documentée : passer le cluster à 3 nœuds et fixer le paramètrediscovery.zen.minimum_master_node à N/2 + 1, soit 2 dans notre cas.
Ce paramètre permet de spécifier que l’élection d’un nouveau maître nécessite la majorité absolue. Scindé en deux, un cluster de 2 nœuds n’aurait pas pu élire de maître. Jusque-là maître, le Nœud 1 se serait mis en attente de la reconnexion réseau. Le cluster aurait perdu sa haute-disponibilité : aucun des nœuds n’aurait pu desservir les requêtes de recherche.
Avec 3 nœuds, l’isolement d’un nœud vis-à-vis de ses 2 compères aurait permis de conserver un cluster actif. A noter que le 3ième nœud peut être configuré pour ne pas héberger de données (paramètrenode.data à false). Il joue alors uniquement le rôle d’arbitre.
IDF
Pour calculer le score d’un document, Elasticsearch se base notamment sur l’Inverse Document Frequency (IDF). La formule statistique sous-jacente à l’IDF peut se traduire en une phrase : la fréquence d’un terme influe sur son score. Et plus précisément : plus le terme est rare dans les documents indexés, plus il est pertinent et son score est élevé. En soit, ce critère parait être du bon sens. Mais dans des applications de gestion nécessitant une précision accrue, cela n’est pas toujours le résultat souhaité.
Prenons le cas d’une recherche par nom et prénom. Plus rares, les personnes avec le nom Antoine sortent avant ceux qui ont le prénom Antoine. A l’inverse, les personnes ayant le prénom Martin sortent avant ceux qui ont le nom Martin. Or, fonctionnellement, il nous a été demandé de privilégier le nom de famille. Le besoin métier nécessite donc d’augmenter le poids du nom par rapport au prénom. C’est précisément ce que permettent les boosts. Le plus difficile est de trouver le bon ratio. Pour se faire, des données et une volumétrie de production sont indispensables. Le boost à donner à chaque champ va être déterminé de manière empirique par exécution successive de requêtes de recherche.
L’IDF peut également poser des problèmes de précision lorsqu’un index est partitionné en plusieurs shards. Techniquement, un shard correspond à un index physique Lucene. Chaque shard dispose donc de sa propre répartition des fréquences des termes.
En fonction des autres documents indexés dans le même shard, le même document peut donc avoir un score différent.
Pour pallier à ce problème, Elasticsearch permet de réaliser des recherches de type DFS Query Then Fetch. Est ajoutée une phase initiale consistant à demander à chaque shard la fréquence des termes et documents à rechercher. Une fréquence globale à tout l’index peut alors être calculée.
Bien entendu, ce calcul n’est pas neutre en termes de performance.
PARTITIONNEMENT
Le partitionnement (ou sharding) est une fonctionnalité phare d’Elasticsearch. C’est ce qui permet à un cluster d’être tolérant aux pannes et de devenir hautement scalable.
Pour autant, utiliser le partitionnement apporte un certain nombre d’inconvénients spécifiques aux systèmes distribués. En plus d’éventuelles pertes de performance ou de dégradations de l’occupation mémoire, une requête de recherche distribuée sur plusieurs shards peut souffrir des symptômes suivants :
- Nombre d’éléments des facettes inexacts (bien que la précision peut être améliorée à partir de la version 0.90.6)
- Ordre incorrect des éléments d’une facette
- Scoring potentiellement différents sur deux partitions
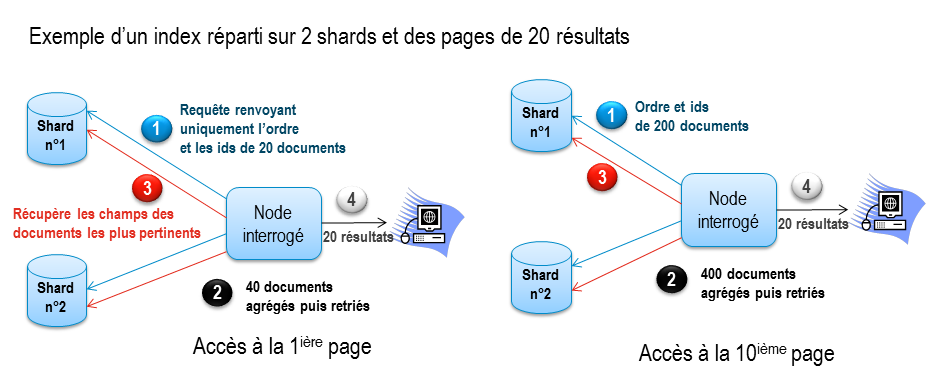
Par ailleurs, il est connu par l’équipe en charge du développement d’Elasticsearch que partitionnement et pagination ne font pas bon ménage. En effet, sans routage efficace, le coût nécessaire pour trier les documents croît exponentiellement en fonction du numéro de page demandé. Le diagramme ci-dessous met en évidence cette complexité :
Malgré toutes les problématiques abordées dans ce billet, j’aimerais conclure ce retour d’expérience en précisant qu’Elasticsearch nous a donné entière satisfaction. Les temps de réponse sont au rendez-vous, de l’ordre de quelques millisecondes. Et les utilisateurs en sont grandement satisfaits.
Avant de se lancer dans sa mise en œuvre, il faut garder à l’esprit que chaque utilisation d’Elasticsearch est singulière. En effet, les techniques employées pour indexer des articles de presse ou des logs ne sont pas les mêmes que celles utilisées pour indexer des données métier. Aussi, s’entourer d’un expert en moteurs de recherche est un réel atout pour assurer la réussite d’un projet.
Références :
Belle reconnaissance. Cet article a été cité sur le bog d’Elasticsearch : http://www.elasticsearch.org/blog/2013-12-18-this-week-in-elasticsearch/