
Pour les besoins d’un workshop sur Elasticsearch, je me suis amusé à indexer une encyclopédie musicale et à mettre en ligne une petite application HTML 5 permettant de réaliser des recherches.
Comme source de données musicale, j’ai opté pour MusicBrainz qui est une plateforme ouverte collectant des méta-données sur les artistes, leurs albums et leurs chansons puis les mettant à disposition du publique.
Pour indexer les données depuis une base PostgreSQL, j’ai privilégié Spring Batch au détriment d’une river. Pour l’IHM, j’ai adapté un prototype basé sur AngularJS, jQuery et Bootstrap qu’avait réalisé Lucian Precup pour la Scrum Day 2013. La mise en ligne de l’index Elasticsearch m’aura permis de tester la plateforme Cloud OpenShift de Redhat.
Cet article a pour objectif de décrire les différentes étapes qui m’ont été nécessaires pour réaliser ma démo et d’expliquer ce que j’ai librement rendu accessible sur GitHub et Internet.
Vue d’ensemble
Le diagramme suivant présente l’architecture mise en place.
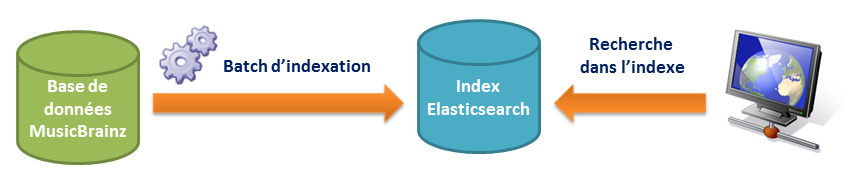
Un batch d’indexation se connecte via JDBC à la base de données de MusicBrainz et indexe les albums de musique dans Elasticsearch. Une application HTML 5 permet d’interroger l’index Elasticsearch.
Base de données MusicBrainz
A l’instar d’IMDb pour le cinéma, MusicBrainz est une base de données dédiée à la musique. Artistes, groupes de musiques, albums, pochettes et chansons issus du monde entier y sont référencés. Outre la base de données musicale, MusicBrainz propose également une interface graphique permettant d’effectuer des recherches, de consulter les données et de participer à l’enrichissement de la base. Last.fm, The Guardian ou bien encore la BBC s’interfacent avec MusicBrainz.
Parce que la base PostgreSQL du sites MusicBrainz.org n’est pas accessible depuis Internet mais également dans le souci de pouvoir réaliser ma démo déconnecté du réseau, j’ai cherché à pouvoir installer la base de données en locale. MusicBrainz propose 2 solutions :
- Télécharger l’image d’une machine virtuelle du serveur MusicBrainz ou
- Télécharger la dernière archive de la base PostgreSQL est l’installer en suivant les instructions du INSTALL.md
Pour ma part, j’ai opté pour la solution la plus simple : installer une VM. Disponible au format OVA, elle peut être déployée aussi bien dans VirtualBox ou que dans VMWare. Le guide d’installation de la VM terminé, 2 étapes seront ensuite nécessaires pour que le host puisse accéder à la base PostgreSQL :
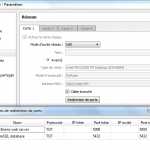 Configurer la redirection de port : VirtualBox permet de rediriger les connexions TCP établies sur un port de l’host vers un autre port de la VM. La base PostgreSQL écoutant sur le port 5432, la règle suivante peut être ajoutée via l’interface de VirtualBox : PostgreSQL database – TCP – host : 5432 / guest : 5432
Configurer la redirection de port : VirtualBox permet de rediriger les connexions TCP établies sur un port de l’host vers un autre port de la VM. La base PostgreSQL écoutant sur le port 5432, la règle suivante peut être ajoutée via l’interface de VirtualBox : PostgreSQL database – TCP – host : 5432 / guest : 5432 - Configurer PostgreSQL : par mesure de sécurité, la base PostgreSQL ne permet pas d’accès distant. Pour que le batch exécuté depuis l’OS hôte puisse s’y connecter, ces instructions doivent être suivies. Démarrer la VM, s’y connecter (login : vm / musicbrainz) et éditer les 2 fichiers de configuration ph_hba.conf et postgresql.conf.

Depuis l’hôte, il est à présent possible de se connecter à la base à partir de n’importe quel client SQL (SQuireL, pgAdmin …). Utiliser les paramètres de connexion suivants :
- URL : jdbc:postgresql://localhost:5432/musicbrainz
- Login : musicbrainz / musicbrainz
Le batch Java est désormais capable de récupérer les données à indexer.
Serveur Elasticsearch en local
Le batch se connecte à un cluster Elasticsearch. L’installation d’un cluster est donc nécessaire, que ce soit sur votre poste de développement ou sur une autre machine. Installer un serveur Elasticsearch est on ne peut plus simple. Quelques lignes de commandes suffisent. Pour davantage d’explications, je vous renvoie à l’article Premiers pas avec ElasticSearch de Tanguy Leroux. Au vu de la volumétrie des données et de la faible charge, un seul nœud suffit amplement.
Le batch d’indexation
Le batch n’indexe pas toute la base de données MusicBrainz. Il se cantonne aux albums de musique qui sont un sous ensemble des release groups. Seuls les albums « principaux » sont indexés. Single, EP, Compilation, Live ou autre Remix ne sont pas indexés.
Le batch d’indexation est composé d’un seul job Spring Batch. La configuration des beans d’infrastructure sur lesquels s’appuie le batch est répartie dans les fichiers applicationContext-datasource.xml, applicationContext-elasticsearch.xml et applicationContext-batch.xml. Y sont déclarés :
- la source de données MusicBrainz et son gestionnaire de transaction,
- un client Elasticsearch déclaré via la fabrique de beans Spring mise à disposition par David Pilato dans le projet spring-elasticsearch,
- un JobRepository en mémoire et un JobLauncher Spring Batch.
Déclaré dans le fichier applicationContext-job.xml, le job musicAlbumJob est décomposé en 4 étapes successives :
- Suppression d’un éventuel précédent index
- Création de l’index musicalbum
- Définition du type de document album
- Indexation dans Elasticsearch
La définition du job ne comporte aucune difficulté :
<job id="musicAlbumJob" xmlns="http://www.springframework.org/schema/batch">
<step id="deleteIndexIfExists" next="createIndexSettings">
<tasklet ref="deleteIndexTasklet" />
</step>
<step id="createIndexSettings" next="createIndexMapping">
<tasklet ref="createIndexSettingsTasklet" />
</step>
<step id="createIndexMapping" next="indexMusicAlbum">
<tasklet ref="createIndexMappingTasklet" />
</step>
<step id="indexMusicAlbum">
<!-- Executes partition steps locally in separate threads of execution -->
<batch:partition step="indexMusicAlbumPartition" partitioner="partitionerMusicAlbum">
<batch:handler grid-size="${batch.partition}" task-executor="batchTaskExecutor" />
</batch:partition>
</step>
</job> A noter ligne 31 que le batch profite du mécanisme de partitionnement présenté dans le précédent billet Parallélisation de traitements batchs. Chacun des beans référencés par les steps sont définis dans le même fichier de configuration Spring. Les 3 premières étapes sont implémentés à l’aide de tasklets :
<bean id="deleteIndexTasklet" class="com.javaetmoi.core.batch.tasklet.DeleteElasticIndexTasklet"
p:esClient-ref="esClient" p:indexName="${es.index}" />
<bean id="createIndexSettingsTasklet" class="com.javaetmoi.core.batch.tasklet.CreateElasticIndexSettingsTasklet"
p:esClient-ref="esClient" p:indexName="${es.index}" p:indexSettings="${es.settings.filename}" />
<bean id="createIndexMappingTasklet" class="com.javaetmoi.core.batch.tasklet.CreateElasticIndexMappingTasklet"
p:esClient-ref="esClient" p:indexName="${es.index}" p:indexMapping="${es.mapping.filename}" p:mappingType="${es.mapping.type}" /> Utilisant l’API Java d’Elasticsearch, ces tasklets sont assez génériques pour être réutilisées sur d’autres projets. En attendant d’apporter qui sait ma contribution au projet spring-batch-elasticsearch d’Olivier Bazoud, je les ai mis à disposition dans la version 0.2 du projet spring-batch-toolkit.
A titre d’exemple, voici un extrait de la tasklet CreateElasticIndexSettingsTasklet :
public class CreateElasticIndexSettingsTasklet implements Tasklet {
private static final Logger LOG = LoggerFactory.getLogger(CreateElasticIndexSettingsTasklet.class);
private Client esClient;
private String indexName;
private Resource indexSettings;
@PostConstruct
public void afterPropertiesSet() {
Assert.notNull(esClient, "esClient must not be null");
Assert.notNull(indexName, "indexName must not be null");
Assert.notNull(indexSettings, "indexSettings must not be null");
}
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
LOG.debug("Creating the index {} settings", indexName);
String source = IOUtils.toString(indexSettings.getInputStream(), "UTF-8");
CreateIndexRequestBuilder createIndexReq = esClient.admin().indices().prepareCreate(indexName);
createIndexReq.setSettings(source);
CreateIndexResponse response = createIndexReq.execute().actionGet();
if (!response.isAcknowledged()) {
throw new RuntimeException("The index settings has not been acknowledged");
}
esClient.admin().indices().refresh(new RefreshRequest(indexName)).actionGet();
LOG.info("Index {} settings created", indexName);
return RepeatStatus.FINISHED;
}
/**
* Sets the Elasticsearch client used to defined index settings.
*
* @param esClient
* Elasticsearch client
*/
public void setEsClient(Client esClient) {
this.esClient = esClient;
}
/**
* Sets the name of the index where documents will be stored
*
* @param indexName
* name of the Elasticsearch index
*/
public void setIndexName(String indexName) {
this.indexName = indexName;
}
/**
* Sets the JSON resource defining index settings.
*
* @param indexSettings
* Spring resource descriptor, such as a file or class path resource.
*/
public void setIndexSettings(Resource indexSettings) {
this.indexSettings = indexSettings;
}
} Le bean de partition indexMusicAlbumPartition s’appuie quant à lui sur un chunk Spring Batch composé d’un reader, d’un writer et d’un processor composite :
<!-- Read music albums from database then index them into ElasticSearch -->
<batch:step id="indexMusicAlbumPartition">
<tasklet transaction-manager="musicBrainzTransactionManager">
<chunk reader="musicAlbumReader" processor="musicAlbumProcessor" writer="musicAlbumWriter"
commit-interval="${batch.commit.interval}" retry-limit="3">
<retryable-exception-classes>
<include class="org.elasticsearch.client.transport.NoNodeAvailableException" />
<include class="org.elasticsearch.transport.ReceiveTimeoutTransportException" />
</retryable-exception-classes>
</chunk>
<listeners>
<listener>
<bean class="com.javaetmoi.core.batch.listener.LogStepListener" scope="step"
p:commitInterval="${batch.commit.interval}"/>
</listener>
</listeners>
</tasklet>
</batch:step> Dans le fichier properties de configuration du batch, la taille des lots (commit-interval) est fixé à 5000 albums.
Le bean musicAlbumReader utilise la classe JdbcCursorItemReader de Spring Batch pour exécuter la requête SQL chargée de lire les albums. Cette requête effectue une jointure entre 10 tables et filtre sur des critères permettant de ramener un ResultSet dans lequel un album ne correspond qu’à une seule ligne. Aucune agrégation de lignes n’est donc à réaliser par le reader. L’enrichissement de l’album avec des données multi-valuées (ex : tags) est réalisé dans la phase de traitement.
Pour comprendre la requête, le modèle physique de données de MusicBrainz est consultable en ligne.
<bean id="musicAlbumReader" class="org.springframework.batch.item.database.JdbcCursorItemReader" scope="step"
p:dataSource-ref="musicBrainzDataSource" p:rowMapper-ref="albumRowMapper">
<property name="sql">
<value><![CDATA[
SELECT
release_group.id AS albumId,
release_group.gid AS albumGid,
release_group.type AS albumPrimaryTypeId,
release_name.name AS albumName,
artist_name.name AS artistName,
artist.gid AS artistGid,
artist.type as artistTypeId,
artist.begin_date_year artistBeginDateYear,
artist.gender as artistGenderId,
area.name as artistCountryName,
artist_meta.rating artistRatingScore,
artist_meta.rating_count artistRatingCount,
release_group_meta.first_release_date_year albumYear,
release_group_meta.rating albumRatingScore,
release_group_meta.rating_count albumRatingCount
FROM
artist
INNER JOIN artist_credit_name
ON artist_credit_name.artist = artist.id
INNER JOIN artist_credit
ON artist_credit.id = artist_credit_name.artist_credit
INNER JOIN release_group
ON release_group.artist_credit = artist_credit.id
INNER JOIN release_name
ON release_name.id = release_group.name
INNER JOIN artist_name
ON artist.name = artist_name.id
INNER JOIN area
ON artist.area = area.id
LEFT OUTER JOIN release_group_secondary_type_join
ON release_group_secondary_type_join.release_group = release_group.id
LEFT OUTER JOIN artist_meta
ON artist.id = artist_meta.id
LEFT OUTER JOIN release_group_meta
ON release_group_meta.id = release_group.id
WHERE
release_group.type = '1'
AND artist_credit.artist_count = 1
AND release_group_secondary_type_join.secondary_type IS NULL
AND release_group.id >= ? and release_group.id <= ?
]]></value>
</property>
<property name="preparedStatementSetter">
<bean class="org.springframework.batch.core.resource.ListPreparedStatementSetter">
<property name="parameters">
<list>
<!-- SPeL parameters order is important because it referes to "where album_id >= ? and album_id <= ?" -->
<value>#{stepExecutionContext[minValue]}</value>
<value>#{stepExecutionContext[maxValue]}</value>
</list>
</property>
</bean>
</property>
</bean> Le ResultSet est mappé à l’aide de la classe AlbumRowMapper implémentant l’interface RowMapper de Spring JDBC. Une instance de a classe Album est retournée en sortie du reader.
public class Album {
private Integer id;
private String gid;
private String name;
private ReleaseGroupPrimaryType type;
private Integer year;
private Rating rating = new Rating();
private Artist artist = new Artist();
private List<String> tags; A ce stade, la liste des tags utilisés dans MusicBrainz pour qualifier le genre musical d’un album est vide.
Le bean musicAlbumProcessor est composé de 2 traitements successifs matérialisés par 2 classes : EnhanceAlbumProcessor et MusicAlbumDocumentProcessor. La première exécute une requête JDBC pour charger les tags de l’album. Le 2nd transforme la classe Album en un document indexable dans Elasticsearch.
<bean id="musicAlbumProcessor" class="org.springframework.batch.item.support.CompositeItemProcessor">
<property name="delegates">
<list>
<bean class="com.javaetmoi.elasticsearch.musicbrainz.batch.item.EnhanceAlbumProcessor" />
<bean class="com.javaetmoi.elasticsearch.musicbrainz.batch.item.MusicAlbumDocumentProcessor"
p:documentType="${es.mapping.type}" />
</list>
</property>
</bean> La classe MusicAlbumDocumentProcessor implémente indirectement l’interface ItemProcessor de Spring Batch. Elle prend en entrée un Album et le transforme EsDocument. La classe EsDocument modélise un document indexable dans Elasticsearch. Elle comporte un identifiant, un type, un contenu et éventuellement une version. Cette classe est suffisamment générique pour avoir été factorisé dans le projet spring-batch-toolkit.
public class EsDocument {
private String id;
private String type;
private Long version;
private XContentBuilder contentBuilder;
/**
* EsDocument constructor.
*
* @param type
* type of the Elasticsearch document
* @param contentBuilder
* Elasticsearch helper to generate JSON content.
*/
public EsDocument(String type, XContentBuilder contentBuilder) {
this.type = type;
this.contentBuilder = contentBuilder;
}
protected String getId() {
return id;
}
/**
* Set the ID of a document which identifies a document.
*
* @param id
* ID of a document (may be <code>null</code>)
*/
public void setId(String id) {
this.id = id;
}
protected XContentBuilder getContentBuilder() {
return contentBuilder;
}
protected String getType() {
return type;
}
/**
* Sets the version, which will cause the index operation to only be performed if a matching
* version exists and no changes happened on the doc since then.
*
* @param version
* version of a document
* @see http://www.elasticsearch.org/blog/versioning/
*/
protected void setVersion(Long version) {
this.version = version;
}
protected boolean isVersioned() {
return version !=null;
}
public Long getVersion() {
return version;
}
} Le type XContentBuilder fait partie de l’API Java d’Elasticsearch. Il permet de construire en mémoire la représentation d’un objet JSON. La classe abstraite EsDocumentProcessor dont hérite MusicAlbumDocumentProcessor implémente le pattern template method et pilote la création du EsDocument. La construction de l’objet JSON a été réalisée manuellement en utilisant les méthodes startObject, field, array et endObject exposées par le XContentBuilder. Comme alternative, Jackson aurait pu être utilisé pour sérialiser la classe Album en JSON.
Le bean musicAlbumWriter termine le traitement batch. Il utilise la fonctionnalité de requêtes en masse (bulk request) d’Elasticsearch pour indexer simultanément tous les documents lus dans un chunk (soit ici 5000). Factorisée elle aussi dans le projet spring-batch-toolkit, la classe EsDocumentWriter concentre le code :
/**
* Index several documents in a single bulk request.
*/
public class EsDocumentWriter implements ItemWriter<EsDocument> {
private static final Logger LOG = LoggerFactory.getLogger(EsDocumentWriter.class);
private Client esClient;
private String indexName;
private Long timeout;
@PostConstruct
public void afterPropertiesSet() {
Assert.notNull(esClient, "esClient must not be null");
Assert.notNull(indexName, "indexName must not be null");
}
@Override
public final void write(List<? extends EsDocument> documents) throws Exception {
BulkRequestBuilder bulkRequest = esClient.prepareBulk();
for (EsDocument doc : documents) {
IndexRequestBuilder request = esClient.prepareIndex(indexName, doc.getType()).setSource(
doc.getContentBuilder());
request.setId(doc.getId());
if (doc.isVersioned()) {
request.setVersion(doc.getVersion());
}
bulkRequest.add(request);
}
BulkResponse response;
if (timeout != null) {
response = bulkRequest.execute().actionGet(timeout);
} else {
response = bulkRequest.execute().actionGet();
}
processResponse(response);
}
private void processResponse(BulkResponse response) {
if (response.hasFailures()) {
String failureMessage = response.getItems()[0].getFailureMessage();
throw new ElasticSearchException("Bulk request failed. First failure message: " + failureMessage);
}
LOG.info("{} documents indexed into ElasticSearch in {} ms", response.getItems().length,
response.getTookInMillis());
}
/**
* Sets the Elasticsearch client used for bulk request.
*
* @param esClient
* Elasticsearch client
*/
public void setEsClient(Client esClient) {
this.esClient = esClient;
}
/**
* Sets the name of the index where documents will be stored.
*
* @param indexName
* name of the Elasticsearch index
*/
public void setIndexName(String indexName) {
this.indexName = indexName;
}
/**
* Waits if necessary for at most the given time for the computation to complete, and then
* retrieves its result, if available.
*
* @param timeout
* the maximum time in milliseconds to wait
*/
public void setTimeout(Long timeout) {
this.timeout = timeout;
}
} En sortie, voici un exemple du document JSON représentant l’album “Achtung Baby” du groupe U2 :
Mapping Elasticsearch
Comme expliqué précédemment, le batch est chargé de créer l’index musicalbum. Outre le nombre de shards et de réplicas, le fichier es-index-settings.json déclare les filtres et les analyseurs utilisés pour indexer puis rechercher des albums.
Le filtre myEdgeNGram et l’analyseur myPartialNameAnalyzer sont par exemple utilisés par l’autosuggestion des résultats de recherche :
"analysis": {
"filter": {
"myEdgeNGram": {
"side": "front",
"max_gram": 10,
"min_gram": 1,
"type": "edgeNGram"
}
},
"analyzer": {
"myStandardAnalyzer": {
"filter": [
"standard",
"lowercase",
"asciifolding"
],
"type": "custom",
"tokenizer": "standard"
},
"myPartialNameAnalyzer": {
"filter": [
"standard",
"lowercase",
"asciifolding",
"myEdgeNGram"
],
"type": "custom",
"tokenizer": "standard"
},Le fichier es-index-mappings.json précise à Elasticsearch comment indexer les différents champs de l’EsDocument construit à partir d’un Album. Ce sont les usages de recherche qui guident la réalisation du fichier de mapping. Par exemple, le nom d’un album sera indexé de 2 manières à l’aide d’une propriété de type multi_field : l’une pour la recherche fulltext et l’autre pour l’autosuggestion.
{
"_source": {
"enabled": "true",
"compress": "true"
},
"properties": {
"id": {
"type": "string",
"analyzer": "myIdAnalyzer"
},
"name": {
"type": "multi_field",
"fields": {
"name": {
"type": "string",
"analyzer": "myStandardAnalyzer"
},
"start": {
"search_analyzer": "myStandardAnalyzer",
"index_analyzer": "myPartialNameAnalyzer",
"type": "string"
}
}
},
"year": {
"type": "multi_field",
"fields": {
"year": {
"type": "date",
"format": "year"
},
"string": {
"type": "string",
"analyzer": "myBasicAnalyzer"
}
}
},
"rating": {
"type": "object",
"properties": {
"score": {
"type": "integer"
},
"count": {
"type": "integer"
}
}
},
"tags": {
"type": "string",
"index_name": "tag"
},
"artist": {
"type": "object",
"properties": {
"name": {
"type": "multi_field",
"fields": {
"name": {
"type": "string",
"analyzer": "myStandardAnalyzer"
},
"start": {
"search_analyzer": "myStandardAnalyzer",
"index_analyzer": "myPartialNameAnalyzer",
"type": "string"
}
}
},
"type_id": {
"type": "integer"
},
"type_name": {
"type": "string"
},
"begin_date_year": {
"type": "date",
"format": "year"
},
"country_name": {
"type": "string",
"analyzer": "myStandardAnalyzer"
},
"gender": {
"type": "string",
"analyzer": "myBasicAnalyzer"
},
"rating": {
"type": "object",
"properties": {
"score": {
"type": "integer"
},
"count": {
"type": "integer"
}
}
}
}
}
}
}Tests unitaires
Avant d’exécuter le batch sur la base de données MusicBrainz, le test unitaire TestMusicAlbumJob m’aura permis d’éprouver le code. La structure du schéma de la base MusicBrainz est reproduite dans une base de données en mémoire H2. Elle est alimentée avec la discographie de U2. Pour se faire, la librairie open source DbSetup a été mise une nouvelle fois à contribution. Une instance Elasticsearch embarquée est démarrée par le test. Le batch est exécuté. Le test vérifie simplement que le nombre de documents indexés correspond au nombre d’albums de U2. En complément, l’exécution d’une requête de recherche aurait permis de valider le mapping.
Exécution du batch
Comme son nom l’indique, la classe IndexBatchMain fournit la méthode main permettant d’exécuter le batch en ligne de commande. Quelques étapes suffisent :
- Démarrer un serveur Elasticsearch
- Démarrer la base de données MusicBrainz database ou la VM l’hébergeant
- git clone https://github.com/arey/musicbrainz-elasticsearch.git
- Personnaliser si besoin le fichier es-musicbrainz-batch.properties
- mvn install
- mvn exec:java
Quelques minutes plus tard, quelques 265 169 albums sont indexés.
Démo
Pour exploiter l’index nouvellement créé, rien de tel qu’une petite interface en HTML 5. Pour se faire, Lucian Precup m’a autorisé à adapter une page qu’il avait mis au point dans le cadre de l’atelier Construisons un moteur de recherche tenu lors de la Scrum Day 2013. Réalisée en AngularJS, jQuery et Boostrap, cette page propose une zone de recherche full-text, offre de l’autosuggestion et affiche le résultat de recherche de manière paginée. Quelques filtres et directives Angular ont été ajoutés pour, par exemple, gérer les appréciations des mélomanes. La capture d’écran ci-dessous donne un aperçu du rendu graphique :
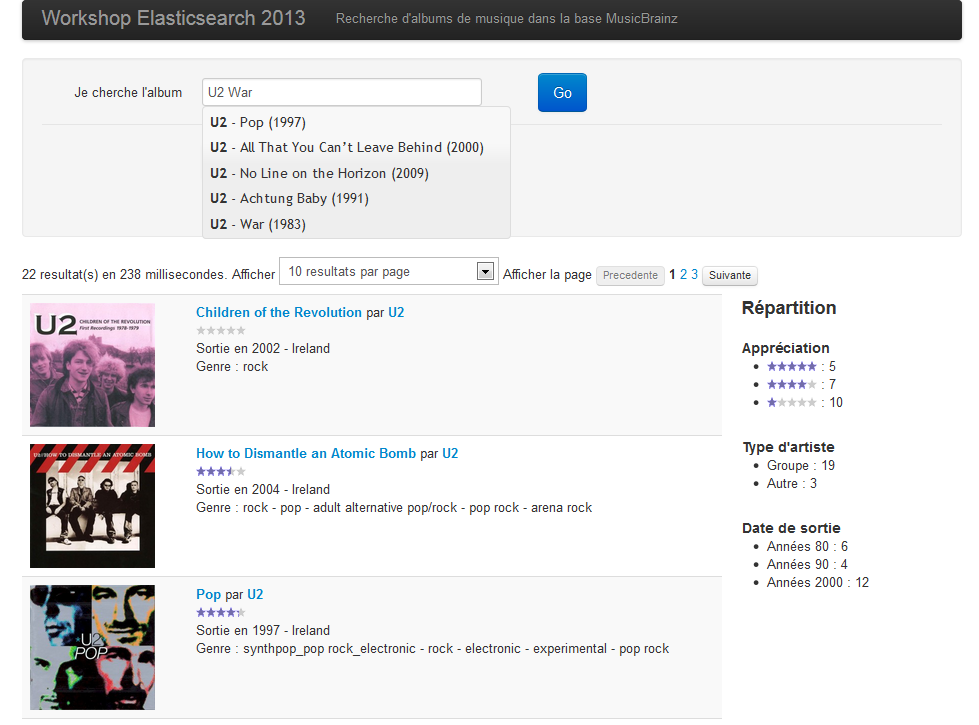
Déployée sur OVH, l’application Angular est accessible à l’adresse http://musicsearch.javaetmoi.com/
Requêtes de recherche
La recherche utilisée pour l’autosuggestion repose sur une query_string analysant le nom de l’album, le nom de l’artiste et la date de sortie de l’album. Pour les noms, elle utilise 2 champs : celui pour la recherche exacte (ex: artist.name) et celui pour la recherche de type « commence par » (ex : artist.name.start). La surbrillance est activée sur les 3 critères.
Le gist 7436834 propose la commande curl équivalente :
curl -XPOST 'http://es.javaetmoi.com/musicalbum/album/_search?pretty' -d '
{
"fields": [
"artist.name",
"id",
"name",
"year.string"
],
"query": {
"query_string": {
"fields": [
"name",
"name.start",
"year.string",
"artist.name",
"artist.name.start"
],
"query": "U2",
"use_dis_max": false,
"auto_generate_phrase_queries": true,
"default_operator": "OR"
}
},
"highlight": {
"number_of_fragments": 0,
"pre_tags": [
"<b>"
],
"post_tags": [
"</b>"
],
"fields": {
"artist.name": {},
"name": {},
"year.string": {}
}
}
}' Voici un extrait du résultat retourné par Elasticsearch:
{
"took" : 13,
"timed_out" : false,
"_shards" : { "total" : 1, "successful" : 1, "failed" : 0 },
"hits" : {
"total" : 22,
"max_score" : 9.11103,
"hits" : [ {
"_index" : "musicalbum",
"_type" : "album",
"_id" : "c6b36664-7e60-3b3e-a24d-d096c67a11e9",
"_score" : 9.11103,
"fields" : {
"id" : "c6b36664-7e60-3b3e-a24d-d096c67a11e9",
"artist.name" : "U2",
"name" : "War"
},
"highlight" : {
"artist.name" : [ "U2" ]
}
}, …La recherche fulltext utilise quant à elle le type de recherche fuzzy_like_this permettant une recherche approximative sur le nom de l’album, le nom de l’artiste et la date de sortie de l’album. Trois facettes de types différents permettent d’afficher la répartition du nombre de résultats en fonction du type d’artiste (terms facet), des appréciations (histogram facet) et de la décennie (range facet).
Le gist 7436893 présente la commande curl équivalente :
curl -XPOST 'http://es.javaetmoi.com/musicalbum/album/_search?pretty' -d '
{
"from": 0,
"size": 10,
"query": {
"bool": {
"must": [
{
"fuzzy_like_this": {
"fields": [
"name",
"artist.name",
"year.string"
],
"like_text": "U2 war",
"min_similarity": 0.7,
"prefix_length": 1
}
}
]
}
},
"facets": {
"artist_type": {
"terms": {
"field": "artist.type_id"
}
},
"album_rating": {
"histogram": {
"key_field": "rating.score",
"interval": 20
}
},
"album_year": {
"range": {
"field": "year",
"ranges": [
{ "to": 1970},
{ "from": 1970, "to": 1980},
{ "from": 1980, "to": 1990},
{ "from": 1990, "to": 2000},
{ "from": 2000, "to": 2010},
{ "from": 2010 }
]
}
}
}
}' Voici un extrait du résultat retourné par Elasticsearch :
{
"took" : 57,
"timed_out" : false,
"_shards" : { "total" : 1, "successful" : 1, "failed" : 0 },
"hits" : {
"total" : 539,
"max_score" : 5.985128,
"hits" : [ {
"_index" : "musicalbum",
"_type" : "album",
"_id" : "c6b36664-7e60-3b3e-a24d-d096c67a11e9",
"_score" : 5.985128, "_source" : {"id":"c6b36664-7e60-3b3e-a24d-d096c67a11e9","name":"War","year":1983,"tags":["rock","album rock","alternative pop/rock","classic pop and rock","pop/rock"],"rating":{"score":79,"count":9},"artist":{"name":"U2","id":"a3cb23fc-acd3-4ce0-8f36-1e5aa6a18432","type_id":2,"type_name":"Group","begin_date_year":"1976","country_name":"Ireland","rating":{"score":87,"count":21}}}
}, ... ]
},
"facets" : {
"artist_type" : {
"_type" : "terms",
"missing" : 6, "total" : 533, "other" : 0,
"terms" : [ {
"term" : 2,
"count" : 407
}, {
"term" : 1,
"count" : 120
}, {
"term" : 3,
"count" : 6
} ]
},... ]
}
}
}Dans le Cloud avec OpenShift
A la recherche d’un hébergeur me permettant d’installer mon index en ligne, je suis tombé sur le billet Searching with ElasticSearch on OpenShift de Marek Jelen, évangéliste OpenShift. C’était l’occasion de découvrir l’offre Cloud de RedHat, et cela sans sortir ma carte bancaire. En effet, OpenShift offre 3 Gems limitées à 512 Mo de RAM et de 1 Go d’espace disque. Avec un index de 160 Mo, c’était amplement suffisant.
Les explications du billet sont claires. Parti du cartouche Do-It-Yourself 0.1 contenant une simple distribution Linux, l’installation d’Elasticsearch se fait classiquement. Des variables systèmes prédéfinies doivent être utilisées pour spécifier l’adresse IP (OPENSHIFT_DIY_IP), le port HTTP (OPENSHIFT_DIY_PORT) et le répertoire d’installation (OPENSHIFT_DATA_DIR).
Si vous le souhaitez, l’installation des plugins eshead et bigdesk est possible.
Afin de résoudre l’exception BindException[Address already in use] au démarrage d’Elasticsearch, j’ai suivi les préconisations postées dans un commentaire par ewindsor.
Une fois Elasticsearch démarré, seul le port HTTP est accessible depuis Internet. C’est le port utilisé par l’IHM de recherche. Le port utilisé par le client TCP Elastisearch n’est quant à lui pas accessible. Le Batch d’indexation s’exécutant en local ne peut donc pas alimenter directement le cluster Elasticsearch. Par facilité, je me suis contenté d’uploader par SFTP mon index local (répertoire data\musicbrainz) sur le serveur OpenShift.
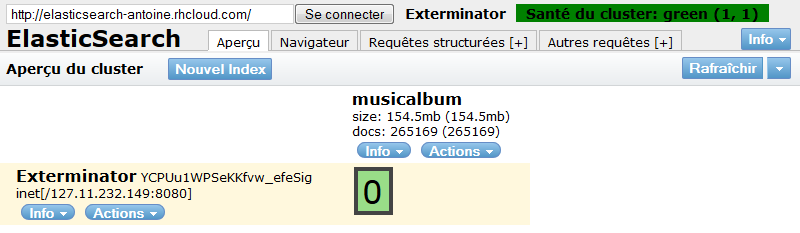
Un redémarrage d’Elasticsearch et l’index est visible via Eshead :
Le plugin Jetty pour Elasticsearch et le cartouche Nginx pour OpenShift permettent de sécuriser l’accès au serveur Elasticsearch, rendant possible la configuration d’un reverse proxy avec authentification basic HTTP.
Pour terminer, OpenShift permet d’associer un nom de domaine à une Gem. Ainsi, le nom de domaine es.javaetmoi.com pointe sur le serveur Nginx.
L’application Angular http://musicsearch.javaetmoi.com/ fait appel à l’API REST d’Angular exposée sur l’URL http://es.javaetmoi.com/musicalbum/album/_search
Conclusion
Ce billet nous aura permis d’aborder de bout en bout la mise en ligne d’une application basée sur Elasticsearch : de l’indexation des données par batch à leur consultation dans votre navigateur.
En moins d’une heure, l’index Elasticsearch aura été mis en ligne sur OpenShift, le PaaS / IaaS de Redhat. La disponibilité d’un cartdrige OpenShift pour Elasticsearch permettrait d’accélérer son déploiement. A noter que mon cluster Elasticsearch n’est formé que d’un seul nœud. Je n’ai pas vérifié s’il était possible d’installer un cluster Elasticsearch sur plusieurs serveurs.
Vous l’aurez remarqué, l’index musicalbum créé par le batch est figé. Pour aller plus loin, il aurait été intéressant d’automatiser sa mise à jour régulière. La base de données Musicbrainz est capable de se synchroniser toutes les heures avec la base principale. Il serait donc possible de reconstruire périodiquement l’index en utilisant, par exemple, un mécanisme d’alias pour ne pas interrompre le service de recherche. La base répliquée et le batch aurait pu être installés sur une 3ième Gem OpenShift. Resterait alors à régler la communication entre le batch et le serveur Elasticsearch. RedHat a dû prévoir la possibilité d’ouvrir un port entre 2 Gems. Dans le cas contraire, un client Java utilisant l’API REST d’indexation permettrait de contourner le blocage du port utilisé pour la communication TCP d’Elasticsearch.
Cet article est référencé sur le blog d’Elasticsearch : http://www.elasticsearch.org/blog/2013-11-2-this-week-in-elasticsearch Belle récompense 🙂