Cet article explique comment intégrer un chatbot utilisant l’IA générative dans une application de gestion codée en Java.
Nous nous appuierons sur le framework Open Source LangChain4j, une adaptation Java de la célèbre librairie python LangChain, visant à simplifier l’intégration de grands modèles de langage (LLM). LangChain4j permet de créer des agents conversationnels, des assistants virtuels (comme notre chatbot), ou des applications capables d’effectuer des analyses de texte et de répondre en fonction de données contextuelles, le tout sans devoir écrire de code complexe et avec un haut niveau d’abstraction. Elle facilite notamment l’utilisation des API des Large Langage Model comme OpenAI et Hugging Face, et propose différents connecteurs pour des bases de données vectorielles, incluant Elasticsearch et Qdrant. Pour accélérer son intégration, LangChain4j propose des extensions pour Quarkus et des starters pour Spring Boot.
Pour illustrer cet article, nous utiliserons l’illustre application démo Spring Petclinic et son récent fork dédié à LangChain4j : spring-petclinic-langchain4j Propulsé par Spring Boot, Spring Petclinic s’appuie sur Spring Data JPA pour l’accès aux données et Thymeleaf pour la couche présentation HTML / CSS / JavaScript. En septembre 2024, Oded Shopen, contributeur en 2020 du fork Spring Petclinic Cloud, a proposé une intégration de Spring AI dans Spring Petclinic. De son travail, est né le projet spring-petclinic-ai. Le repository spring-petclinic-langchain4j est un portage du frameworkSpring AIvers LangChain4j. Y a été ajouté notamment une fonctionnalité de streaming. Extraits du sample, les exemples de code s’appuient sur les versions 3.3 de Spring Boot et 0.35.0 de LangChaing4j.
Démo
Avant de se plonger dans le code Java, je vous propose de voir le résultat final en visionnant ce screencast durant moins de 2 minutes et dans lequel je pose 4 questions à l’assistant :
Impressionnant, non ? Lorsqu’on pose les mêmes questions en français, le chatbot répond en français.
Compte développeur OpenAI
A ce jour, l’application Spring Petclinic LangChain4j supporte OpenAI et son service hébergé sur Azure : Azure OpenAI. Dans cet article, nous nous focaliserons sur l’intégration OpenAI. Pour faire fonctionner ce sample, moyennant quelques euros de crédits, vous aurez besoin d’un compte développeur OpenAI et d’une clé d’API personnelle exportée en tant que variable d’environnement OPENAI_API_KEY.
Si vous ne disposez pas de votre propre clé API OpenAI ou ne souhaitez pas dépenser le moindre centime, vous pouvez utiliser temporairement la clé de démonstration demo que OpenAI fournit gratuitement. Seul le modèle gpt-4o-mini sera alors disponible avec cette clé et le nombre de tokens sera limité à 5000.
export OPENAI_API_KEY=demo
Déclarer les starters Spring Boot
La documentation Spring Boot Integration de LangChain4j explique comment les starters Spring Boot aident à configurer l’usage des larges modèles de langages, des embedding models et des embedding stores par le biais de propriétés à déclarer dans le fichier application.properties (ou application.yaml).
Dans le pom.xml de Spring Petclinic, commençons par déclarer les deux dépendances langchain4j-spring-boot-starter et langchain4j-open-ai-spring-boot-starter :
Le premier starter langchain4j-spring-boot-starter expose la classe d’auto-configuration pour Spring Boot LangChain4jAutoConfig et donne, entre autre, accès à l’annotation @AiService que nous utiliserons dans une prochaine étape.
Le second starter langchain4j-open-ai-spring-boot-starter permet quant à lui de parser et binder les propriétés spécifiques à OpenAI du fichier de configuration application.properties (ex : langchain4j.azure-open-ai.chat-model.api-key). Par transitivité, il tire les artefacts langchain4j-open-ai et dev.ai4j:openai4j. En interne, LangChain4j s’appuie sur le client Java non officiel openai4j permettant de connecter des applications Java à l’API OpenAI.
Configuration OpenAI
Dans une première version du chatbot ne faisant pas encore l’usage du streaming, ajouter au fichier application.properties les 4 propriétés suivantes :
Plus compact et moins cher que le modèle gpt-4o préconisé pour la démo, le modèle gpt-4o-mini peut également être utilisé et sait répondre aux exemples de questions suggérées dans le readme.md.
Spring Boot détermine les beans à instancier en fonction des propriétés déclarées. A titre d’exemple, la classe AutoConfig du starter LangChain4j OpenAI pour Spring Boot, déclare conditionnellement un bean de type OpenAiChatModelimplémentant l’interface agnostique ChatLanguageModellorsque la propriété langchain4j.open-ai.chat-model.api-key est déclarée. Dans la suite de cet article, nous aurons besoin d’un bean de type StreamingChatLanguageModel permettant de streamer la réponse du LLM token par token. Sur le même principe, la propriété langchain4j.open-ai.streaming-chat-model.api-key déclenchera l’instanciation d’un bean de type OpenAiStreamingChatModel implémentant l’interface StreamingChatLanguageModel.
Dans le code métier, l’interaction avec le LLM se fait au travers d’une simple interface Java nommée Assistantet annotée avec l’annotation @AiService. LangChain4j propose un mécanisme similaire à Spring Data et Square Retrofit : on définit de manière déclarative une interface respectant des conventions de nommage et, au runtime, LangChain4j fournit une implémentation de cette interface. Se référer à la documentation AI Services pour davantage d’explications. L’interface Assistant propose une seule et unique méthode chat. Celle-ci accepte une question de l’utilisateur et renvoie la réponse du LLM sous forme de String.
Le bean implémentant cette interface est mise à disposition par Spring et pourra être injecté, par exemple, dans le contrôleur REST.
Prompter un Message Système
Pour répondre à l’utilisateur, nous guidons le comportement du LLM en définissant un « system message » via l’annotation @SystemMessage. Les directives sont externalisées dans le fichier texte system.st :
You are a friendly AI assistant designed to help with the management of a veterinarian pet clinic called Spring Petclinic. Your job is to answer questions about and to perform actions on the user's behalf, mainly around veterinarians, owners, owners' pets and owners' visits. If you need access to pet owners or pet types, list and locate them without asking the user. You are required to answer in a professional manner. If you don't know the answer, politely inform the user, and then ask a follow-up question to help clarify what they are asking. If you do know the answer, provide the answer but do not provide any additional followup questions. When dealing with vets, if the user is unsure about the returned results, explain that there may be additional data that was not returned. Only if the user is asking about the total number of all vets, answer that there are a lot and ask for some additional criteria. For owners, pets or visits - provide the correct data.
Comme expliqué par Oded dans son article de blog, le contexte système doit être régulièrement enrichi et optimisé afin que les réponses soient les plus précises et les plus fiables possibles. Par exemple, afin que le LLM prenne des initiatives sans demander l’aval de l’utilisateur, le message système a été récemment complété avec la directive suivante :
If you need access to pet owners or pet types, list and locate them without asking the user.
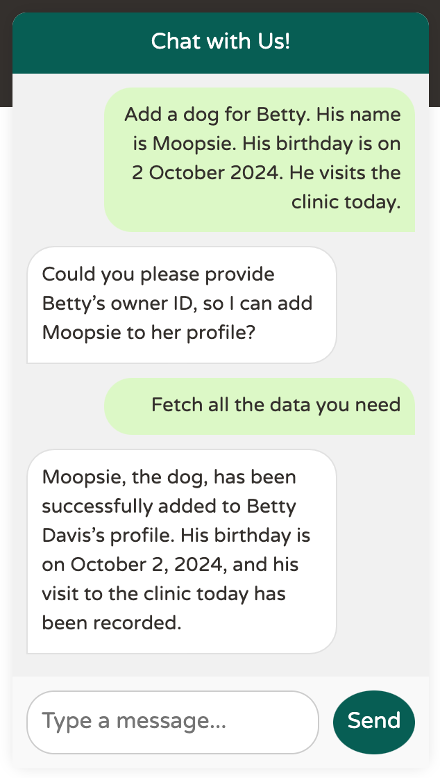
Sans cette directive, le LLM demande l’autorisation de rechercher l’ID de Betty :
Déclarer un contrôleur REST
Le chabot est appelé depuis le navigateur via une API REST. Déclarer un contrôleur Rest AssistantController exposant le endpoint /chat :
Démarrer l’application Spring Boot et vérifier le fonctionnement du chatbot via un simple appel curl :
Paramétrer la mémoire conversationnelle de l’assistant
A ce stade, le chatbot n’a pas encore de mémoire. Il ne peut donc pas s’aider des précédents échanges pour générer une réponse. Voici un des exemples des plus connus :
Pour remédier à ce problème, nous déclarons un bean Spring de type ChatMemory qui conserve l’historique des 10 derniers messages.
Le prénom donné lors du premier appel est désormais réutilisé par le LLM lors du deuxième appel :
Par défaut, les messages sont sauvegardés en mémoire dans un InMemoryChatMemoryStore. En cas de redémarrage de l’application, les messages volatiles sont perdus. Avec plusieurs instances de la même application sans affinité de sessions, l’historique des messages est réparti sur différentes JVM. Cela pose également problème. Une solution consiste à implémenter l’interface ChatMemoryStore afin de persister les messages en base ou dans un cache distribué. Se référer à l’exemple ServiceWithPersistentMemoryForEachUserExample.java.
Supporter plusieurs utilisateurs
A ce stade, la même instance de ChatMemory est utilisée pour toutes les invocations du service d’IA. Cette approche a des limites et ne fonctionnera pas avec plusieurs utilisateurs. Chaque utilisateur a besoin de sa propre instance de ChatMemory pour maintenir sa conversation individuelle. Une solution proposée par LangChain4j consiste à utiliser un ChatMemoryProvider :
Chaque utilisateur est associé à un memoryId qui lui est dédié et dispose donc de sa propre ChatMemory.
La signature de la méthode chat de l’interface Assistant prend désormais un second paramètre nommé memoryId, annoté avec l’annotation @MemoryIdet de type UUID v4. Le paramètre userMessage est quant à lui annoté avec @UserMessage :
Certaines réponses d’OpenAI sont formattés en Markdown. Côté front, la librairie MarkedJS permet de convertir le markdown en HTML. Elle est ajoutée dans la configuration maven en tant que webjar :
Afin d’interagir avec le code métier de l’application, les développeurs peuvent proposer aux LLM d’appeler des fonctions, en l’occurrence du code Java. L’appel de fonctions personnalisées renforce la capacité des LLM à fournir des réponses plus pertinentes et contextuelles. Le LLM peut, par exemple, accéder aux données de l’application. Le LLM n’appelle pas directement les fonctions : le modèle produit une sortie de données structurées qui spécifie le nom de la fonction à appeler ainsi que les arguments suggérés. Les fonctions sont appelées par l’application Java ayant appelée le LLM. A noter que tous les LLM ne supportent pas encore l’appel de fonctions.
LangChain4j facilite et standardise l’appel de fonctions via les Tools. Deux niveaux d’abstraction sont proposés :
Low-level, en utilisant la classe ToolSpecification pour décrire les fonctions au LLM : nom, description, paramètres d’entrée / sortie.
High-level, à l’aide des services d’IA et des méthodes Java annotées @Tool
Nous mettrons en œuvre celui de haut niveau permettant d’annoter n’importe quelle méthode Java avec l’annotation @Tool. LangChain4j génère automatiquement les ToolSpecifications à partir de la signature des méthodes annotées. Lors de l’appel du LLM, la description des fonctions qui sont mises à sa disposition lui sont transmises. Lorsque le LLM décide d’appeler une fonction, LangChain4j exécute automatiquement la méthode Java appropriée et sa valeur de retour est renvoyée au LLM. Sous la forme d’un simple bean Spring, la classe AssistantTool expose les fonctions que le LLM pourra invoquer pour récupérer des données de référence, lister les propriétaires ou bien encore ajouter en base un animal de compagnie. Commençons par déclarer une function nommée getAllOwners :
@ComponentpublicclassAssistantTool{privatefinalOwnerRepositoryownerRepository;publicAssistantTool(OwnerRepositoryownerRepository){this.ownerRepository= ownerRepository;}@Tool("List the owners that the pet clinic has: ownerId, name, address, phone number, pets")publicOwnersResponsegetAllOwners(){Pageablepageable=PageRequest.of(0,100);Page<Owner>ownerPage=ownerRepository.findAll(pageable);returnnewOwnersResponse(ownerPage.getContent());}}record OwnersResponse(List<Owner> owners){}
En interne, la classe AssistantTool utilise le repository Spring Data JPA OwnerRepository utilisé par l’application. Apposée au niveau de l’annotation @Tool, la description aide le LLM à comprendre quand appeler la fonction. La fonction getAllOwners() ne prend pas de paramètre. Elle retourne le record OwnersResponse qui contient une liste de Owner. La classe Owner est une entité JPA existante et utilisée pour l’IHM. Cet exemple démontre donc les capacités de LangChain4j à réutiliser le code existant. Une fois la fonction appelée, LangChain4j convertit le record OwnersResponse au format JSON pour que le LLM puisse le traiter.
A noter que la méthode getAllOwners n’aurait pas sa place dans une application d’entreprise. L’application démo Spring Petclinic compte seulement 10 propriétaires. Renvoyer toutes les données de la base ne pose donc pas de problème de performance. Néanmoins, dans une vraie application de gestion, proposer une méthode de recherche multi-critères serait préférable. C’est ce que propose l’issue #9.
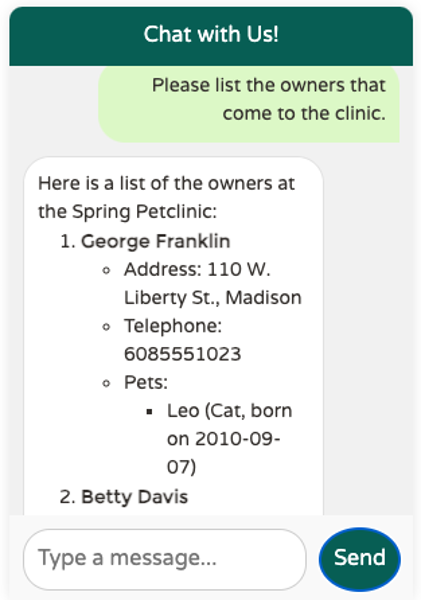
Interrogeons à présent le chatbot avec la question « Please list the owners that come to the clinic. » et regardons le flux d’échange entre l’application Petclinic et OpenAI.
Au préalable, dans le fichier application.properties, nous avons activé les logs des requêtes et réponses envoyées à OpenAI :
Lors du 1er appel à OpenAI, à côté de la question saisie par l’utilisateur dans le fenêtre de chat, la fonction getAllOwners est proposée dans une liste de tools.
Log partiel de la requête #1 :
- method: POST - url: https://api.openai.com/v1/chat/completions - headers: [Authorization: Bearer xxxx], [User-Agent: langchain4j-openai] - body: { "model" : "gpt-4o", "messages" : [ { "role" : "system", "content" : "You are a friendly AI assistant designed to help with the management of a veterinarian pet clinic called Spring Petclinic…" }, { "role" : "user", "content" : "\"Please list the owners that come to the clinic.\" } ], "temperature" : 0.7, "tools" : [{ "type" : "function", "function" : { "name" : "getAllOwners", "description" : "List the owners that the pet clinic has: ownerId, name, address, phone number, pets", "parameters" : { "type" : "object", "properties" : { }, "required" : [ ] } } }, …
Comme attendu, OpenAI demande à l’application d’appeler la function getAllOwners. Log partiel de la réponse #1 :
LangChain4j fait aussitôt appel à la méhtode getAllOwners du bean AssistantTool. Le résultat est sérialisé en JSON et placé dans l’attribut content lors du second appel au LLM.
OpenAI utilise le résultat de l’appel à la fonction getAllOwners pour générer une réponse présentant une liste de propriétaires d’animaux formatée en markdown :
Log partiel de la réponse #2 :
- status code: 200 - headers: … - body: { "id": "chatcmpl-AOqj0Y9yhJjzYtzV7QMXiBU4URkJ7", "object": "chat.completion", "created": 1730485910, "model": "gpt-4o-2024-08-06", "choices": [ { "index": 0, "message": { "role": "assistant", "content": "Here is a list of the owners at the Spring Petclinic:\n\n1. **George Franklin**\n - Address: 110 W. Liberty St., Madison\n - Telephone: 6085551023\n - Pets: \n - Leo (Cat, born on 2010-09-07)\n\n2. **Betty Davis**\n - Address: 638 Cardinal Ave., Sun Prairie\n - Telephone: 6085551749\n - Pets: \n - Basil (Hamster, born on 2012-08-06)\n\n3. **Eduardo Rodriquez**\n - Address: 2693 Commerce St., McFarland\n - Telephone: 6085558763\n - Pets: \n - Jewel (Dog, born on 2010-03-07)\n - Rosy (Dog, born on 2011-04-17)\n\n4. **Harold Davis**\...", … } ], "usage": { … }
Cette première fonction a montré comment le LLM peut récupérer des données depuis la base de données pour générer sa réponse.
Agent conversationnel
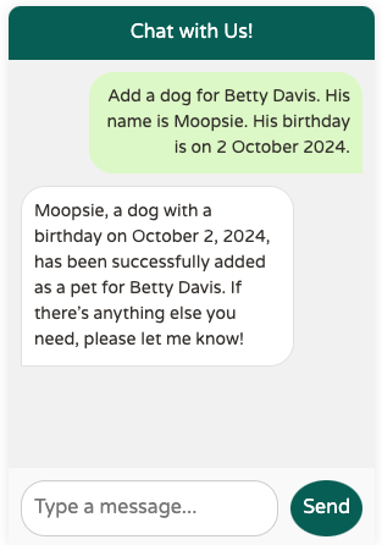
Ajoutons à présent les fonctions permettant à un vétérinaire de déclarer un nouvel animal de compagnie pour l’un de ses clients, en formulant dans le chat la requête suivante :
Add a dog for Betty Davis. His name is Moopsie. His birthday is on 2 October 2024.
Dans la classe AssistantTool, ajoutons une seconde fonction addPetToOwner permettant à un vétérinaire de déclarer un nouvel animal de compagnie à l’un de ses clients :
@Tool("Add a pet with the specified petTypeId, to an owner identified by the ownerId")publicAddedPetResponseaddPetToOwner(AddPetRequest request){Ownerowner=ownerRepository.findById(request.ownerId());owner.addPet(request.pet());this.ownerRepository.save(owner);returnnewAddedPetResponse(owner);}
Cette fois-ci, la méthode accepte un paramètre de type AddPetRequest :
record AddPetRequest(Pet pet,Integer ownerId){}
Pour ajouter un animal de compagnie, le LLM doit connaitre l’identifiant du propriétaire (le ownerId) et les données caractérisant son compagnon. Cet identifiant peut être récupéré par le LLM via l’appel de la fonction getAllOwners. Le LLM doit également savoir comment valoriser les attributs de la classe Pet : name, birthDate, visits et type. Les identifiants du type PetType (ex : 1=cat, 2=dog …) peuvent être listés par le LLM via l’appel de la nouvelle fonction populatePetTypes :
@Tool("List all pairs of petTypeId and pet type name")publicList<PetType>populatePetTypes(){returnthis.ownerRepository.findPetTypes();}
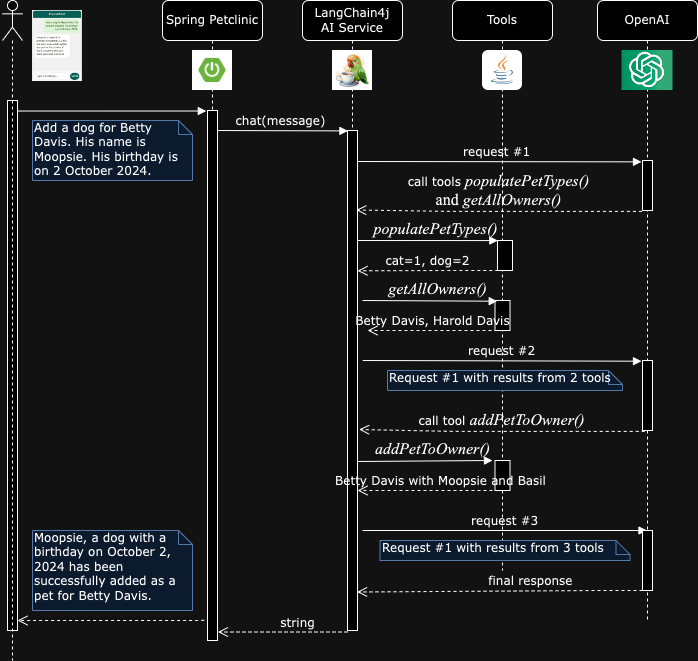
Lorsque OpenAI est interrogé, dans sa première réponse, il demande à LangChain4j d’appeler 2 fonctions / tools. Optimisé, cela évitera les allers-retours :
LangChain4j appelle séquentiellement ces 2 fonctions (paralléliser ces appels serait un axe d’optimisation de notre application : issue #13) puis renvoie les résultats à OpenAI.
De ces 2 appels de fonctions, OpenAI déduit l’identifiant de Betty Davis égal à 2 ainsi que l’identifiant d’un chien lui aussi égal à 2. En réponse, il demande à LangChain4j d’appeler la fonction addPetToOwner en lui passant ces deux identifiants, ainsi que le nom et la date de naissance donné par l’utilisateur.
Cette fois-ci, LangChain4j doit passer un paramètre de type AddPetRequest lors de l’appel à la fonction addPetToOwner. La structure de donnée a préalablement été communiquée au LLM lors de la description de la fonction mise à sa disposition :
{"type":"function","function":{"name":"addPetToOwner","description":"Add a pet with the specified petTypeId, to an owner identified by the ownerId","parameters":{"type":"object","properties":{"request":{"type":"object","properties":{"ownerId":{"type":"integer"},"pet":{"type":"object","properties":{"visits":{"type":"array","items":{"type":"object","properties":{"date":{"type":"object","properties":{"month":{"type":"integer"},"year":{"type":"integer"},"day":{"type":"integer"}},"required":[]},"description":{"type":"string"}},"required":[]}},"type":{"type":"object","properties":{},"required":[]},"birthDate":{"type":"object","properties":{"month":{"type":"integer"},"year":{"type":"integer"},"day":{"type":"integer"}},"required":[]}},"required":[]}},"required":[]}},"required":["request"]}}}
Le LLM a structuré en JSON les paramètres d’appel de fonction. La classe DefaultToolExecutor de LangChain4j se charge d’unmarshaller les données JSON. En interne, elle s’appuie sur une librairie JSON (à termes, Jackson doit remplacer Google GSON).
Les résultats des 3 appels de fonction sont renvoyés à OpenAI dans une 3ième et dernière requête. Ce dernier conclue que l’ajout s’est bien passé et récapitule les informations enregistrées.
Voici un diagramme de séquences illustrant les appels que nous venons de décrire :
Response Streaming
La méthode chat() déclarée dans le @AiService renvoie une simple String. L’utilisateur doit attendre que le LLM ait généré l’intégralité de sa réponse avant de recevoir le résultat. Ceci est regrettable lorsqu’on sait qu’un LLM génère du texte un jeton à la fois. La plupart des LLM propose un moyen de diffuser la réponse jeton par jeton au lieu d’attendre que l’ensemble du texte soit généré. Cette possibilité améliore l’expérience de l’utilisateur qui n’a alors pas besoin d’attendre une durée inconnue et peut commencer à lire la réponse presque immédiatement. LangChain4j supporte nativement cette fonctionnalité de Response Streaming. Il sait streamer token par token en utilisant l’interface TokenStream comme type de réponse. Le client peut s’abonner aux flux de jetons renvoyé par le LLM et ainsi être notifié lorsqu’un nouveau jeton est disponible. Modifions la signature de notre méthode :
Remarque : cette version de l’application Spring Petclinic est développée sur une stack non réactive avec Spring MVC. Si elle l’avait été avec Spring Webflux, nous aurions pu utiliser le type Flux<String> à la place de TokenStream.
Le contrôleur REST AssistantController doit à son tour être adapté. De la même manière que sur l’application web ChatGPT, nous utilisons la technologie Server Sent Events (SSE) pour que le serveur envoie au navigateur au fil de l’eau les réponses du LLM. Spring Framework supporte nativement SSE depuis 2015 via la classe SseEmitter, se référer à sa documentation.
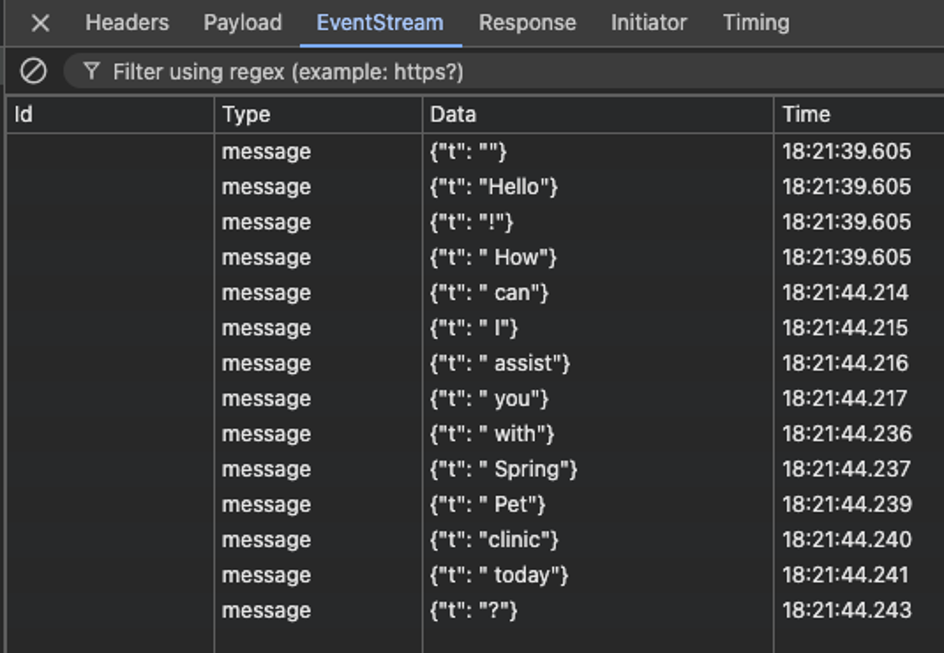
Chaque token est envoyé dans un message structuré en JSON. L’onglet EventStream de Google Chrome donne un aperçu du résultat :
Dans le contrôleur, l’appel à la méthode chat() est fait en asynchrone par un ExecutorService. L’appelant n’est pas bloqué. L’envoie des tokens au client (dans notre cas au navigateur) est assuré par l’appel à la classe SseEmitter.
@RestControllerclassAssistantController{privatestaticfinalLoggerLOGGER=LoggerFactory.getLogger(AssistantController.class);privatefinalAssistantassistant;privatefinalExecutorServicenonBlockingService=Executors.newCachedThreadPool();AssistantController(Assistantassistant){this.assistant= assistant;}// Using the POST method due to chat memory capabilities@PostMapping(value="/chat/{user}")publicSseEmitterchat(@PathVariableUUIDuser,@RequestBodyStringquery){SseEmitteremitter=newSseEmitter();nonBlockingService.execute(()->assistant.chat(user, query).onNext(message ->{try{sendMessage(emitter, message);}catch(IOExceptione){LOGGER.error("Error while writing next token", e);emitter.completeWithError(e);}}).onComplete(token ->emitter.complete()).onError(error ->{LOGGER.error("Unexpected chat error", error);try{sendMessage(emitter,error.getMessage());}catch(IOExceptione){LOGGER.error("Error while writing next token", e);}emitter.completeWithError(error);}).start());return emitter;}privatestaticvoidsendMessage(SseEmitteremitter,Stringmessage)throwsIOException{Stringtoken= message// Hack line break problem when using Server Sent Events (SSE).replace("\n","<br>")// Escape JSON quotes.replace("\"","\\\"");emitter.send("{\"t\": \""+ token +"\"}");}}
En interne, pour streamer la réponse du LLM, LangChain4j utilise l’interface StreamingChatLanguageModel (à la place de ChatLanguageModel). Dans le fichier de configuration application.properties, les propriétés langchain4j.open-ai.chat-model.xxx sont renommées en langchain4j.open-ai.streaming-chat-model.xxx :
L’ensemble des tools mis à disposition du LLM par Petclinic lui permettent d’accéder aux données des propriétaires, de leurs animaux et de leurs visites. Rien sur les vétérinaires officiant dans la clinique. Afin de permettre aux utilisateurs de poser des questions sur les vétérinaires, nous allons exploiter une autre fonctionnalité majeure des LLM et de LangChain4j : la génération augmentée par récupération, connue en anglais sous l’acronyme RAG pour Retrieval Augmented Generation. Un RAG permet de fournir à un LLM des informations complémentaires dont il pourrait avoir besoin pour répondre aux requêtes des utilisateurs, en particulier lorsqu’il s’agit de données plus récentes ou de contenus privés non accessibles lors de son entraînement. Un RAG permet d’utiliser la recherche sémantique. Par exemple, dans la question suivante, l’utilisateur utilise des synonymes des spécialités déclarées en base de données dans le référentiel : radiography (radiographie) pour radiology (radiologue) et odontology (odontologie) pour dentistry (dentiste).
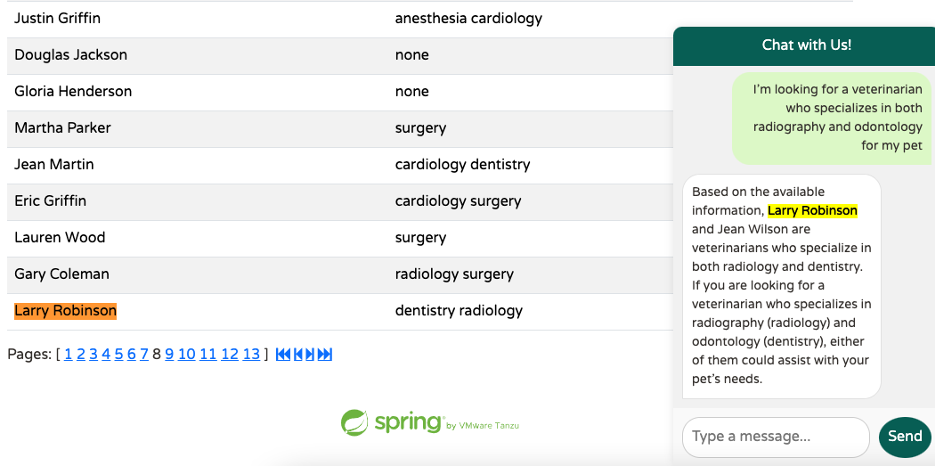
Question : « I’m looking for a veterinarian who specializes in both radiography and odontology for my pet »
A l’aide du RAG, l’application Petclinic retrouve 2 vétérinaires ayant la spécialité de radiology et de dentistry. L’utilisation d’un index inversé Lucene n’aurait pas permis d’arriver à ce résultat.
Pour intégrer le RAG à Petclinic, nous devons procéder en 2 étapes : la phase d’ingestion (indexation) des vétérinaires et la phase de requêtage (retrieval en anglais). La documentation de LangChain4j sur le support des RAG propose deux diagrammes illustrant les étapes d’indexation et de retrieval.
Ingestion d’embeddings
Afin de pouvoir être utilisées par le LLM, les données des 3 tables vets, specialties et vet_specialties doivent préalablement être ingérées et stockées dans une base de données vectorielle. PostgreSQL avec l’extension pgVector est probablement le choix le plus populaire. Greenplum et Qdrant sont 2 autres bases de données vectorielles. LangChain4j supporte plus de 25 bases vectorielles avec des niveaux plus ou moins avancés.
Lors de la phase d’ingestion, les données textuelles des vétérinaires (nom, prénom et spécialités) sont converties en vecteurs multidimensionnels appelés embedding puis stockés dans la base vectorielle. La documentation de LangChain4j parle d’Embedding Stores. Pour notre application d’exemple, par simplicité, nous allons utiliser la base vectorielle en mémoire proposée par LangChain4j. Dans la classe de configuration Spring AssistantConfiguration, commençons par déclarer le bean de type InMemoryEmbeddingStore :
Le modèle all-MiniLM-L6-v2 est un modèle de langage basé sur la famille MiniLM conçue par Microsoft. Entrainé pour la similarité sémantique et les recherches de phrases, ce modèle de 86 Mo est compact et optimisé pour offrir des performances élevées en termes de qualité d’encodage de phrases, tout en restant léger et rapide. Il semble parfait pour notre chatbot et la recherche de similarité.
Une fois le choix du modèle arrêté, ajoutons sa dépendance dans le pom.xml :
L’ingestion des données vétérinaires est réalisée en moins d’une seconde au démarrage de l’application Petclinic via la classe EmbeddingStoreInit :
@ComponentpublicclassEmbeddingStoreInit{privatefinalLoggerlogger=LoggerFactory.getLogger(EmbeddingStoreInit.class);privatefinalInMemoryEmbeddingStore<TextSegment>embeddingStore;privatefinalEmbeddingModelembeddingModel;privatefinalVetRepositoryvetRepository;publicEmbeddingStoreInit(InMemoryEmbeddingStore<TextSegment>embeddingStore,EmbeddingModelembeddingModel,VetRepositoryvetRepository){this.embeddingStore= embeddingStore;this.embeddingModel= embeddingModel;this.vetRepository= vetRepository;}@EventListenerpublicvoidloadVetDataToEmbeddingStoreOnStartup(ApplicationStartedEventevent){Pageablepageable=PageRequest.of(0,Integer.MAX_VALUE);Page<Vet>vetsPage=vetRepository.findAll(pageable);StringvetsAsJson=convertListToJson(vetsPage.getContent());EmbeddingStoreIngestoringestor=EmbeddingStoreIngestor.builder().documentSplitter(newDocumentByLineSplitter(1000,200)).embeddingModel(embeddingModel).embeddingStore(embeddingStore).build();ingestor.ingest(newDocument(vetsAsJson));}publicStringconvertListToJson(List<Vet>vets){ObjectMapperobjectMapper=newObjectMapper();try{// Convert List<Vet> to JSON stringStringBuilderjsonArray=newStringBuilder();for(Vetvet: vets){StringjsonElement=objectMapper.writeValueAsString(vet);jsonArray.append(jsonElement).append("\n");// For use of the// DocumentByLineSplitter}returnjsonArray.toString();}catch(JsonProcessingExceptione){logger.error("Problems encountered when generating JSON from the vets list", e);returnnull;}}}
La classe EmbeddingStoreInit fait appel au VetRepository pour charger tous vétérinaires de la base, les marshalle en un gros Document JSON puis fait appel à la classe EmbeddingStoreIngestor de LangChain4j. Ce EmbeddingStoreIngestor est configuré avec le modèle d’embedding, la base vectorielle où les embeddings seront stockés et un DocumentByLineSplitter chargé de découper le volumineux document JSON en TextSegment censé améliorer la qualité des recherches de similarité et de réduire la taille et le coût d’une invite envoyée au LLM.
Une fois le EmbeddingStoreIngestor construit, la méthode ingest() est appelée pour ingérer le document. Comme le montre les logs ci-dessous, ce dernier est découpé en 33 segments de texte. Les embeddings sont calculés sur les 33 segments puis stockés dans la base vectorielle :
EmbeddingStoreIngestor : Starting to ingest 1 documents EmbeddingStoreIngestor : Documents were split into 33 text segments EmbeddingStoreIngestor : Starting to embed 33 text segments EmbeddingStoreIngestor : Finished embedding 33 text segments EmbeddingStoreIngestor : Starting to store 33 text segments into the embedding store EmbeddingStoreIngestor : Finished storing 33 text segments into the embedding store
Requêtage des embeddings
A présent que l’ensemble des données vétérinaires sont stockées en base vectorielle sous forme d’embeddings, configurons l’application pour que le chatbot utilise ces données lors de son dialogue avec le LLM.
Pour utiliser les fonctionnalités RAG, la classe @AiService Assistant passe par l’interface RetrievalAugmentor et son implémentation par défaut mise à disposition par LangChain4j. Cette interface est chargée d’enrichir le ChatMessage avec des contenus pertinents extraits d’une ou plusieurs sources de données, comme par exemple notre base vectorielle en mémoire. Pour avoir un aperçu des composants manipulés par le RetrievalAugmentor, je vous invite à consulter le schéma du paragraphe Advanced RAG de la documentation de LangChain4j. On y voit l’utilisation d’un ContentRetriever pour interroger une base vectorielle, un moteur de recherche, une base SQL ou bien encore un moteur de recherche.
Dans Petclinic, nous déclarons un bean ContentRetriever de type EmbeddingStoreContentRetriever chargé de récupérer des données vétérinaires dans notre base vectorielle :
En redémarrant l’application Petclinic puis en posant une question au chatbot, on s’aperçoit que LangChain4j complète le prompt de l’utilisateur en concaténant à la suite de sa question la liste des vétérinaires issus de la base vectorielle et qui se rapprochent sémantiquement de sa question :
- method: POST - url: https://api.openai.com/v1/chat/completions - headers: [Accept: text/event-stream], [Authorization: Bearer xxx], [User-Agent: langchain4j-openai] - body: { "model" : "gpt-4o", "messages" : [ { "role" : "system", "content" : "You are a friendly AI assistant …" }, { "role" : "user", "content" : "\"I'm looking for a veterinarian who specializes in both radiography and odontology for my pet \"\n\ content Answer using the following information:\n{\"id\":158,\"firstName\":\"Lauren\",\"lastName\":\"Wood\",\"new\":false,\"specialties\":[{\"id\":2,\"name\":\"surgery\",\"new\":false}]}\n{\"id\":159,\"firstName\":\"Gary\",\"lastName\":\"Coleman\",\"new\":false,\"specialties\":[{\"id\":1,\"name\":\"radiology\",\"new\":false},{\"id\":2,\"name\":\"surgery\",\"new\":false}]}\ …" } ], "temperature" : 0.7, … }
Routage de questions
Le dernier point présenté dans cet article consiste à utiliser la fonctionnalité Query Router de LangChain4j. Interroger la base vectorielle pour chaque question n’a pas nécessairement d’intérêt. Par exemple pour un simple « Hello » ou une question portant uniquement sur les propriétaires. Comme son nom le laisse supposer, un Query Router est responsable de router une requête utilisateur vers le ou les ContentRetriever appropriéssi nécessaire.
L’implémentation de l’interface QueryRouter est à la charge du développeur. Pour déterminer si la question d’un utilisateur porte sur les vétérinaires, on aurait pu utiliser une simple recherche de la chaine de caractère « vet ». D’une part, on n’aurait pas supporter le multilingue et d’autre part on aurait interrogé la base vectorielle si l’utilisateur nous avait posé une question hors contexte sur, par exemples, les vétérans. Qui mieux qu’un LLM peut déterminer la sémantique de la question ? La classe VetQueryRouter fait un premier appel au LLM pour répondre à la question « Is the following query related to one or more veterinarians of the pet clinic? ». On demande au LLM de répondre par oui ou par non. Sé réponse détermine si l’usage du Embedding Store est nécessaire. Nul besoin ici d’utiliser de streaming.
classVetQueryRouterimplementsQueryRouter{privatestaticfinalLoggerLOGGER=LoggerFactory.getLogger(VetQueryRouter.class);privatestaticfinalPromptTemplatePROMPT_TEMPLATE=PromptTemplate.from(""" Is the following query related to one or more veterinarians of the pet clinic? Answer only 'yes' or 'no'. Query: {{it}}""");privatefinalContentRetrievervetContentRetriever;privatefinalChatLanguageModelchatLanguageModel;publicVetQueryRouter(ChatLanguageModelchatLanguageModel,ContentRetrievervetContentRetriever){this.chatLanguageModel= chatLanguageModel;this.vetContentRetriever= vetContentRetriever;}@OverridepublicCollection<ContentRetriever>route(Queryquery){Promptprompt=PROMPT_TEMPLATE.apply(query.text());AiMessageaiMessage=chatLanguageModel.generate(prompt.toUserMessage()).content();LOGGER.debug("LLM decided: {}",aiMessage.text());if(aiMessage.text().toLowerCase().contains("yes")){returnsingletonList(vetContentRetriever);}returnemptyList();}}
La déclaration du VetQueryRouter au niveau de AssistantConfiguration passe par l’utilisation de la méthode builder de la classe DefaultRetrievalAugmentor :
Petclinic utilisant désormais le ChatLanguageModel et le StreamingChatLanguageModel, le fichier de configuration application.properties doit être complété :
Dans les logs applicatifs, un premier appel est désormais envoyé au LLM avant toute autre appel :
- method: POST - url: https://api.openai.com/v1/chat/completions - headers: [Authorization: Bearer sk-Qw...MA], [User-Agent: langchain4j-openai] - body: { "model" : "gpt-4o-mini", "messages" : [ { "role" : "user", "content" : "Is the following query related to one or more veterinarians of the pet clinic?\nAnswer only 'yes' or 'no'.\nQuery: \"I'm looking for a veterinarian who specializes in both radiography and odontology for my pet \"\n" } ], "temperature" : 0.7 }
Conclusion
Cet article aura montré comment intégrer LangChain4j dans une application de gestion basée sur Spring Boot.
Récapitulons les principales fonctionnalités de LangChain4j qui ont été mises en œuvre :
AI Service : définit de manière déclarative l’interface entre notre application Java et un LLM.
Memory : permet d’historiser les conversations entre l’utilisateur et le LLM, supporte le multi-utilisateurs et la persistance.
System prompt : joue un rôle essentiel dans les LLM car il détermine la manière dont les modèles interprètent les requêtes des utilisateurs et y répondent.
Tooling (ou appel de fonction) : permet au LLM d’appeler, si nécessaire, une ou plusieurs méthodes Java de l’application.
Streaming : réponse au fil de l’eau, token par token, en utilisant côté client le Server-Sent Events.
RAG : utilisation d’un embedding store en mémoire pour ingérer les données vétérinaires, faire des recherches de similarité et enrichir le prompt utilisateur en fonction d’une règle de routage.
Personnellement, le développement de la version LangChain4j de Spring Petclinic m’aura permis de contribuer modestement au projet Open Source LangChain4j (PR #49, #50, #51 et #2000).
Je tiens à remercier mon fils Evan pour son montage de ma video Youtube. Merci également à Antonio Goncalves, Julien Dubois, Guillaume Laforge et Valentin Deleplace pour leurs workshops sur LangChain4j avec Azure OpenAI et Gemini.
Si vous souhaitez contribuez à votre tour à Spring Petclinic LangChain4j, des issues vous attendent. L’issue #10 vise notamment à intégrer d’autres LLM que OpenAI et Azure OpenAI. Parmi les candidats potentiels figurent Google Vertex AI Gemini, Ollama ou bien encore Mistral AI. Avis aux amatrices et aux amateurs.
Nous utilisons des cookies pour vous garantir la meilleure expérience sur notre site web. Si vous continuez à utiliser ce site, nous supposerons que vous en êtes satisfait.