
Date : 16 avril 2025
Conférence : Devoxx France 2025
Speaker : José Paumard (Oracle)
Format : Conférence 45 mn
Support : slides sur Speakerdeck
Java Developer Advocate chez Oracle, José Paumard nous présente la nouvelle API Gatherers qui, depuis Java 24, vient se greffer sur l’API Stream Java sortie il y’a 11 ans avec Java 8.
Tout comme l’API Collector, José commence par rappeler que l’API Gatherers est indépendante de l’API Stream. Cette API a été introduite dans Java via la JEP 485 Stream Gatherers conduite par Viktor Klang. Les plus curieux pourront regarder la vidéo Youtube du Deep Dive qu’a animé Viktor lors de la conférence JavaOne qui s’est tenue en mars 2025.
L’article The Gatherer API permet également d’approfondir votre étude des Gatherers. Notez que le site dev.java permet désormais d’exécuter des snippets Java (pas directement dans le navigateur, mais sur un serveur Cloud).
Toutes les classes et interfaces de l’API Gatherers ont été ajoutées au package java.util.stream.

Opérations intermédiaires et terminales d’un Stream
Pour rappel, un Stream se connecte à une source de données (collections, fichier, générateur de nombres aléatoires, regex). Un stream est composé de :
- zéro, une ou plusieurs opérations intermédiaires qui retournent un Stream
- une seule et unique opération terminale qui retourne un résultat et clôture le Sream.
Viktor assimile l’API Stream à celle d’un Builder : on décrit un pipeline d’opérations puis on appelle l’opération terminale pour déclencher son traitement.
Exemples d’opération terminales proposées par l’API Stream :
- reduce() : opération de réduction
- findFirst() : renvoie un objet de type Optional qui encapsule le premier élément du Stream s’il existe, ne consomme pas tous les éléments du Streams.
- collect() : prend en paramètre un Collector
- toList() : méthode raccourcie disponible depuis Java 16
Les Collector permettent de créer ses propres opérations de réduction. Gatherer est le pendant des Collector pour les opérations intermédiaires. Une différence notable est qu’un Collector ne peut pas interrompre un Stream : il ne le connait pas.
Le JDK propose de nombreuses opérations intermédiaires comme map(), filter(), dropWhile(), limit() ou bien encore mapMulti() ajoutée plus récemment. L’API Gatherers va nous permettre de créer nos propres opérations intermédiaires. Ce n’était pas possible jusque-là. Parmi ces opérations intermédiaires, il existe des opérations stateless comme filter() et des opérations statefull come sorted() qui doivent consommer tous les éléments du stream avant de produire quelque chose vers le down stream.
Il n’y avait pas moyen de créer d’opérations intermédiaires jusqu’aux Gatherers.
Que propose l’API Gatherer ?
L’interface générique Gatherer s’appuie sur 3 paramètres :
interface Gatherer<T, A, R> {
Integrator<A, T, R> integrator();
}- T : type des éléments consommés
- A : type mutable utilisé en interne par les Gatherers
- R : type des éléments poussés dans le down stream
Avec sa méthode principale integrator(), José compare l’interface Gatherer à une interface fonctionnelle de type Supplier.
L’interface Gatherer met à disposition 3 interfaces fonctionnelles imbriquées dont nous étudierons le fonctionnement : Downstream, Greedy et Integrator.
Exemple de le l’interface Integrator :
@FunctionalInterface
interface Integrator<A, T, R> {
boolean integrate(A state, T element, Downstream<? super R> downstream);
}Afin de pouvoir utiliser le Gatherer, l’interface Stream de l’API Stream propose désormais depuis Java 24 la méthode gather :
Stream<R> downStream = upstream.gather(gatherer);Le JDK s’enrichit de la classe factory Gatherers (notez son pluriel) utilisées par les différentes implémentations des méthodes of() de l’interface Gatherer.
Publier dans le Downstream
Un Downstream reçoit des données traitées par une opération intermédiaire. C’est le flux de sortie d’un Gatherer.
Voici un exemple de Gatherer chargé de pousser un élément dans le Downstream :
Gatherer<T, ?, R> gatherer = Gatherer.of(
(_, element, downStream) -> downStream.push(element) // returns a boolean
);Le booléen renvoyé en retour est important. Son fonctionnement est subtil : renvoyer false permet l’arrêt du traitement des éléments suivants. Il ne se passe alors plus rien lorsqu’on pousse des éléments au downStream qui n’en accepte désormais plus. Aucune exception n’est levée. Cela peut surprendre.
Dans le jargon de l’API Gatherer, lorsqu’un Integrator retourne directement la valeur du downstream.push(element), on dit qu’il est Greedy. Il traitera nécessairement tous les éléments du Stream. Son exécution est optimisée. Exemple :
Gatherer<T, ?, R> gatherer = Gatherer.of(
Integrator.of((_, element, downstream) -> downstream.push(element))
);Lorsqu’un Integrator n’utilise pas de coupe-circuit et consomme donc l’intégralité des éléments reçus, il est recommandé d’utiliser la méthode factory Integrator.ofGreedy() pour instancier un Integrator :
Gatherer<T, ?, R> gatherer = Gatherer.of(
Integrator.ofGreedy((_, element, downstream) -> downstream.push(element))
);Un Downstream possède un état nommé rejecting. La méthode isRejecting() de l’interface Downstream propose d’y accéder. Cet état a 3 propriétés :
- Commence à false
- Ne peut commuter que de false vers true (ne peut pas se rouvrir)
- L’état de peut commuter que lors d’un push() => règle spécifique aux API du JDK
José nous met en garde : dans un Integrator, l’appel à la méthode isRejecting() ne sert à rien. Il s’agit d’une fausse optimisation qui s’apparente à du code mort.
(_, element, downstream) -> {
if (downstream.isRejecting()) { //
return false; // Condition inutile
} //
return downstream.push(mapper.apply(element));
}José continue sa présentation en nous expliquant les bonnes pratiques à adopter lorsqu’on publie sur le Downstream :
- Ne pas faire de test isRejecting() sur le Downstream
- Privilégiez l’usage de la méthode allMath() plus efficace que takeWhile()
- Fermer les ressources si nécessaire. Lorsque le Stream agit sur un fichier, il faut fermer le fichier et ne pas oublier le try with ressources
Exemple exempté de bugs :
(_, element, downstream) -> {
try (Stream<R> elements = flatMapper.apply(element);) {
return elements.allMatch(downstream::push);
}
}Un Downstream n’est pas un objet thread-safe. Il est donc nécessaire de ne pas générer d’effet de bord sur les données externes. Attention aux race conditions et plus particulièrement dans les parallel streams.
A ce titre, la méthode Gatherer.oSequential() permet de créer un Gatherer séquentiel (non parallélisable).
L’élément state est un état mutable pouvant être utilisé par le Gatherer. En complément de l’Integrator, il est nécessaire de fournir à l’API de création d’un Gatherer un Supplier chargé d’initialiser l’état du state.
Exemple d’un Gatherer limitant le nombre d’éléments et initialisant un compteur :
class Counter { long count = 0L; }
var gatherer = Gatherer.ofSequential(
Counter::new, // the initializer
(state, element, downstream) -> {
if (state.count++ < limit) {
return downstream.push(element);
} else {
return false;
}
});A noter que l’opérateur var retient le type des classes anonymes.
Pour agir sur l’ensemble des données du Gatherer, on peut stocker les éléments dans une collection tel qu’un HashSet dans l’exemple suivant « Distinct Gatherer »:
var gatherer = Gatherer.ofSequential(
() -> new Object() { Set<T> set = new HashSet<>(); },
(state, element, downstream) -> {
if (state.set.add(element)) {
return downstream.push(element);
} else {
return true;
}
});Pour publier l’état final d’un Gatherer, on peut ajouter après l’Initializer et l’Integrator une 3ième lambda de type BiConsumer agitant comme finisher et pouvant consommer tous les éléments du state :
var gatherer = Gatherer.ofSequential(
() -> new Object() { Set<T> set = new TreeSet<>(); },
(state, element, downstream) -> { ... },
(state, downstream) -> { // finisher
state.set.stream().allMatch(downstream::push);
});Les Parallel Gatherers
Les développeurs Java peuvent choisir de construire un Gather supportant ou non le parallélisme et les parallel Streams. A cet effet, 2 méthodes de type fabrique sont à leur disposition :
- Gatherer.of()
- Gatherer.ofSequential()
Pour supporter le parallélisme, l’API Gatherer adopte le principe suivant : un objet state par thread. Cela permet de ne pas utiliser de collections synchronisées dégradant les performances.
Dans chaque Stream parallèle, on a donc autant de state que de threads. A la fin de l’opération intermédiaire, il est nécessaire d’utiliser un Combiner pour combiner tous les états. 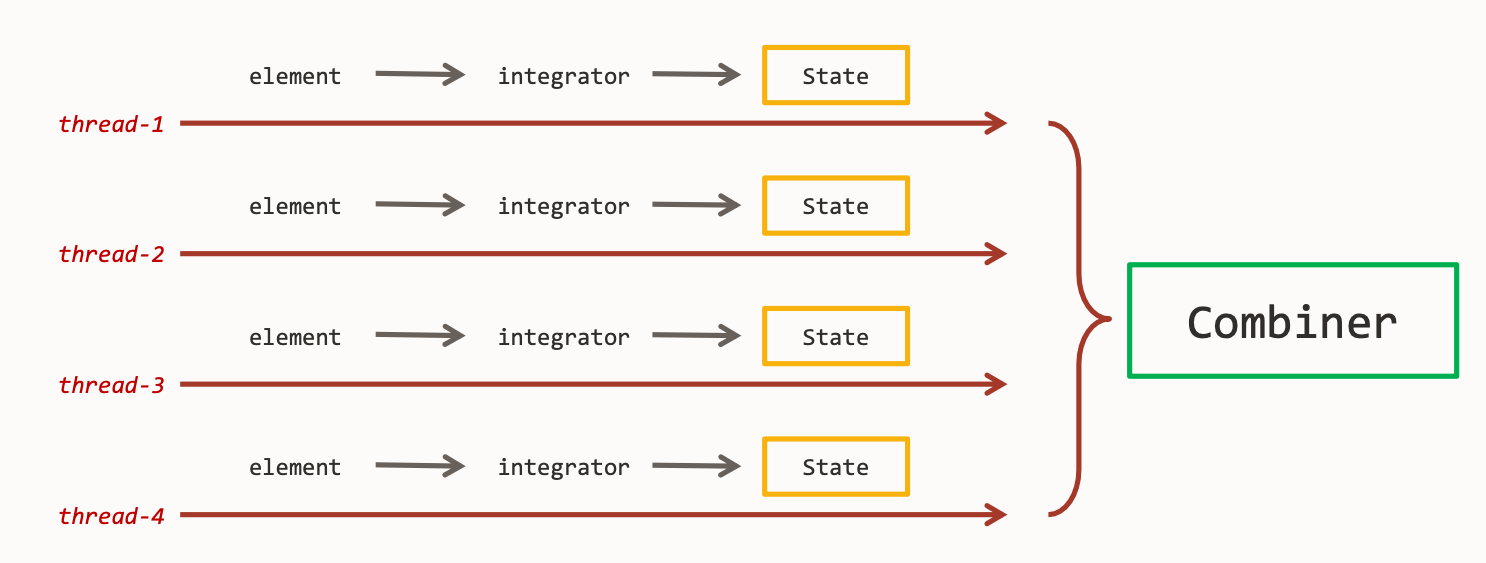
Ce Combiner est un 4ième paramètre à passer à la méthode factory of() :
var gatherer = Gatherer.of(
() -> new Object() { Set<T> set = new HashSet<>(); },
(state, element, downstream) -> { // executed in
state.set.add(element); // different threads
return true;
},
(state1, state2) -> { // combiner
state1.set.addAll(state2.set);
return state1;
},
(state, downstream) -> { // finisher
state.set.allMatch(downstream::push);
}
);Les Sequential Gatherers ne peuvent pas être appelés en même temps depuis différents thhreads. Ils ne possèdent pas de Combiner. Pour autant, José nous explique que l’API Stream est capable de séquencer les appels vers un Sequential Gatherer. Cette fonctionnalité est nouvelle et donc à utiliser avec précaution. Tester les perfs.
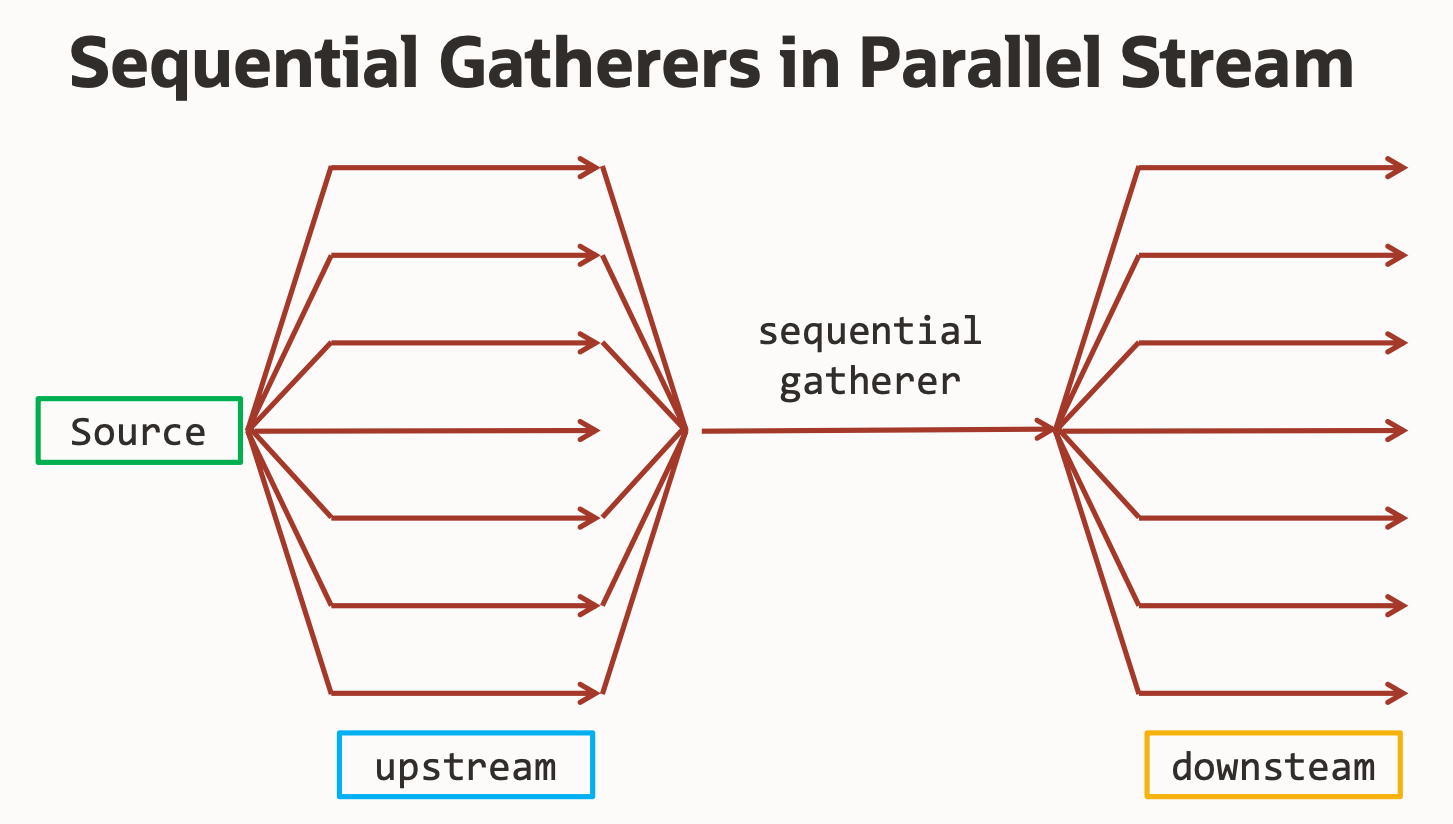
Pour aller plus loin, José nous invite à consulter le repo GitHub SvenWoltmann/stream-gatherers. Le JDK vient avec de nouveaux Gatherers comme scan(), fold() ou bien encore mapConcurrent().
Des librairies tierces comme gatherers4j proposent également leur propres gatherers : reverse(), repeat(n), groupBy(fn) …
Pour conclure, retenons qu’un Gatherer est construit sur 4 éléments. Tous ne sont pas obligatoires.