
EhCache est sans nul doute le framework open source de gestion de cache applicatif le plus populaire parmi les développeurs Java. Polyvalent, EhCache peut être mis en œuvre dans les différentes couches d’une application web :
- Service métier : mise en cache du résultat d’un service métier ou d’un appel de web service
- Présentation : cache de pages ou de fragments de page HTML
Habitués à gérer la sécurité et les transactions de manière déclarative à l’aide d’annotations, le projet open source ehcache-spring-annotations a fait le bonheur des développeurs Spring en 2010 en introduisant l’annotation @Cacheable Hébergé sur Google Code, ce projet n’est aujourd’hui plus maintenu. Il ne supporte pas Spring 4.x. Rattrapant son retard, la version 3.1 du framework Spring a été enrichi de sa propre annotation @Cacheable. Comme à son habitude, Spring permet de s’abstraire de la solution de cache sous-jacente (ex : ConcurrentMap, EhCache, Guava …) en proposant une API générique. Les débuts de cette API ont été difficiles (cf. SPR-10237 à laquelle j’ai participé). Aujourd’hui mature, implémentant la JSR-107 JCache, il n’y a aucune raison pour ne pas migrer dessus. Relativement court , ce billet explique pas à pas comment migrer de ehcache-spring-annotations vers le support de cache du framework Spring.
Lire la suite…
HttpSessionmis à disposition par le conteneur web. Les 2 annotations@Scope("session")et@SessionAttributesen font parties. Dans ce billet, je vous expliquerai le fonctionnement de l’annotation@SessionAttributesqu’il est essentiel de maitriser avant d’utiliser. Nous verrons qu’elle fonctionne de pair avec l’annotation@ModelAttributeet qu’elle permet de simuler une portée conversation. Nous commencerons cet article par rappeler ce qu’est un modèle et nous le terminerons en testant unitairement du code qui utilise@SessionAttributes.
Lire la suite…
Cet article explique comment étendre Spring MVC pour générer le code HTML 5 des champs de saisie (input fields) à partir des annotations Bean Validation (JSR 330) apposées sur des Entités ou de simples DTO.
Dans une application web , valider les écrans de saisie côté client permet de donner un retour rapide à l’utilisateur. Avant HTML 5, le développeur web était bien démuni pour implémenter ces contrôles de surface sur le Navigateur. Certes, HTML 4 permettait de spécifier la taille max des champs de saisie (balise
maxLength) et leur caractère obligatoire ou non (baliserequired). Les autres contrôles effectués côté serveur étaient alors bien souvent recodés en JavaScript à l’aide de jQuery, de CSS et de quelques plugins. Aujourd’hui, HTML 5 se démocratise et le code JavaScript de validation devrait bientôt s’alléger drastiquement. En effet, cette spécification permet de standardiser la validation des champs de saisie côté client. Le développeur a désormais la possibilité de spécifier le type de champs (ex : nombre, date, URL …), des valeurs min et max ou bien encore un pattern de validation à l’aide d’une expression régulière.
Lire la suite…
Dans ce billet, nous verrons comment configurer en Java le contexte Spring d’une application basée sur Spring MVC, Spring Security, Spring Data JPA et Hibernate, et cela sans utiliser la moindre ligne de XML.
Personnellement, je n’ai rien contre la syntaxe XML à laquelle j’étais habitué. D’autant la verbosité de la configuration avait considérablement diminué grâce à l’introduction des namespaces XML et des annotations. Avant d’utiliser la syntaxe Java sur une application d’entreprise, j’étais même sceptique quant aux gains qu’elle pouvait apporter. Aujourd’hui, je comprends mieux son intérêt et pourquoi les projets du portfolio Spring tels Spring Integration 4.0, Spring Web Service 2.2 ou bien Spring Security 3.2 proposent dans leur dernière version un niveau de configuration Java iso-fonctionnel avec leur équivalent XML. Sans compter que le support de la configuration Java leur ouvre la porte d’une intégration plus poussée à Spring Boot, le nouveau fer de lance de Pivotal.
Lire la suite…
Ce billet solutionne un problème rencontré lors de la montée de version du famework Spring de la version 3.2 à la version 4.0. En effet, le déploiement d’une application sous JBoss 5.1 EAP échouait dès l’initialisation du contexte Spring. Plus précisément, une exception était levée lorsque Spring scanne le classpath à la recherche de beans Spring annotés par les annotations @Repository, @Service, @Controller …
Comme le montre la pile d’appel complète ci-dessous, l’exception java.lang.ClassNotFoundException: org.jboss.vfs.VFS est encapsulée dans l’exception java.lang.IllegalStateException: Could not detect JBoss VFS infrastructureCe problème ne m’était initialement pas apparu lors des développements sous Eclipse avec le plugin JBoss Tools pour WTP : Spring n’a aucun mai à trouver les beans d’un WAR ou d’un EAR explosé. Cette erreur s’est manifestée lors du déploiement manuel de l’EAR dans le répertoire deploy de JBoss puis du démarrage du serveur par la commande run.bat.
Lire la suite…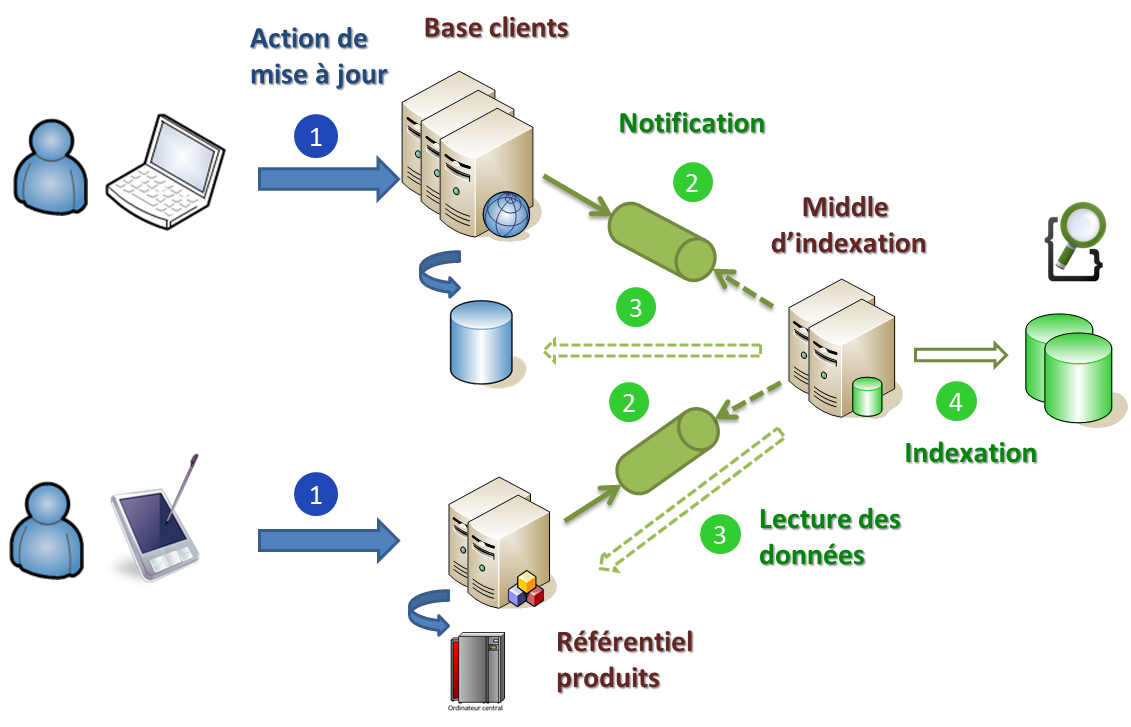
Dans un précédent billet, je vous ai présenté les solutions mises en œuvre sur un projet pour paralléliser un batch d’indexation alimentant un moteur de recherche d’entreprise. Utilisée pour initialiser l’index de recherche puis le resynchroniser quotidiennement, la technique d’intégration par batch ne permet cependant pas d’indexer les données au fil de l’eau. Ce billet aborde précisément cet aspect. En effet, le fil de l’eau ou le quasi temps réel fut dès le départ une exigence forte du métier. Recherches instantanées et auto-complétion révolutionnent le traditionnel formulaire de recherche mettant plusieurs secondes à renvoyer les résultats. Mais au prix de faire des recherches sur des données pouvant dater de J-1 ? Ce n’était pas acceptable ! Un middle d’indexation fut la réponse apportée.
Lire la suite…
Contexte
Récemment, j’ai participé au développement d’un batch capable d’indexer dans le moteur de recherche Elasticsearch des données provenant d’une base de données tierce. Développé en Java, ce batch s’appuie sur Spring Batch, le plus célèbre framework de traitements par lot de l’écosystème Java
Plus précisément, ce batch est décomposé en 2 jobs Spring Batch, très proches l’un de l’autre :- le premier est capable d’initialiser à partir de zéro le moteur de recherche
- et le second traite uniquement les mouvements quotidiens de données.
Problématique
Au cours du traitement batch, l’exécution de la requête par Oracle pour préparer son curseur a été identifiée comme l’opération la plus couteuse, loin devant la lecture des enregistrements en streaming à travers le réseau, leur traitement chargé de construire les documents Lucene à indexer ou leur écriture en mode bulk dans ElasticSearch. A titre d’exemple, sur des volumétries de production, la préparation côté serveur Oracle d’une requête SQL ramenant 10 millions d’enregistrement peut mettre jusqu’à 1h30.
Avec pour objectif que le batch passe sous le seuil de 2h à moindre coût, 2 axes d’optimisations ont été étudiés : diminuer le temps d’exécution par Oracle et diminuer le temps de traitement.
Solutions étudiées
Les optimisations d’un DBA consistant à utiliser des tables temporaires et des procédures stockées n’ont pas été concluantes : trop peu de gains (10 à 20%) pour une réécriture partielle de notre batch, et avec le risque d’engendrer des régressions.
Après mesures et calculs, l’utilisation de la pagination sur des plages de 100, de 1 000 ou même de 10 000 enregistrements a également été écartée. Dans notre contexte, cela aurait dégradé les performances. Le choix de rester sur l’utilisation d’un curseur JDBC a été maintenu.
A cette occasion, nous avons remarqué que les temps de mise en place d’un curseur Oracle pour préparer 1 millions ou 10 millions d’enregistrements étaient du même ordre de grandeur.Utilisant déjà l’une des techniques proposées par Spring Batch pour paralléliser notre traitement batch, pourquoi ne pas refaire appel à ses loyaux services ?
Lire la suite…
