
Parallélisation de traitements batchs
Contexte
Récemment, j’ai participé au développement d’un batch capable d’indexer dans le moteur de recherche Elasticsearch des données provenant d’une base de données tierce. Développé en Java, ce batch s’appuie sur Spring Batch, le plus célèbre framework de traitements par lot de l’écosystème Java
Plus précisément, ce batch est décomposé en 2 jobs Spring Batch, très proches l’un de l’autre :
- le premier est capable d’initialiser à partir de zéro le moteur de recherche
- et le second traite uniquement les mouvements quotidiens de données.
Problématique
Au cours du traitement batch, l’exécution de la requête par Oracle pour préparer son curseur a été identifiée comme l’opération la plus couteuse, loin devant la lecture des enregistrements en streaming à travers le réseau, leur traitement chargé de construire les documents Lucene à indexer ou leur écriture en mode bulk dans ElasticSearch. A titre d’exemple, sur des volumétries de production, la préparation côté serveur Oracle d’une requête SQL ramenant 10 millions d’enregistrement peut mettre jusqu’à 1h30.
Avec pour objectif que le batch passe sous le seuil de 2h à moindre coût, 2 axes d’optimisations ont été étudiés : diminuer le temps d’exécution par Oracle et diminuer le temps de traitement.
Solutions étudiées
Les optimisations d’un DBA consistant à utiliser des tables temporaires et des procédures stockées n’ont pas été concluantes : trop peu de gains (10 à 20%) pour une réécriture partielle de notre batch, et avec le risque d’engendrer des régressions.
Après mesures et calculs, l’utilisation de la pagination sur des plages de 100, de 1 000 ou même de 10 000 enregistrements a également été écartée. Dans notre contexte, cela aurait dégradé les performances. Le choix de rester sur l’utilisation d’un curseur JDBC a été maintenu.
A cette occasion, nous avons remarqué que les temps de mise en place d’un curseur Oracle pour préparer 1 millions ou 10 millions d’enregistrements étaient du même ordre de grandeur.
Utilisant déjà l’une des techniques proposées par Spring Batch pour paralléliser notre traitement batch, pourquoi ne pas refaire appel à ses loyaux services ?
Spring Batch et ses techniques de parallélisation
Comme indiqué dans son manuel de référence, Spring Batch propose nativement 4 techniques pour paralléliser les traitements :
- Multi-threaded Step (single process)
- Parallel Steps (single process)
- Remote Chunking of Step (multi process)
- Partitioning a Step (single or multi process)
Pour optimiser le batch, 2 de ces techniques ont été utilisées.
Le Remote Chunking of Step a été écarté d’office. Dans le contexte client, installer un batch en production est déjà forte affaire. Alors en installer plusieurs interconnectés, je n’ose pas me l’imaginer : à étudier en dernier recours.
Le Multi-threaded Step est sans doute la technique la plus simple à mettre en œuvre. Seule un peu de configuration est suffisante : l’ajout d’un taskExecutor sur le tasklet à paralléliser. La conséquence majeure est que les items peuvent être traités dans le désordre.
Un prérequis à cette technique est que les ItemReader et ItemWiter soient stateless ou thread-safe. La classe de JdbcCursorItemReader de Spring Batch hérite de la classe AbstractItemCountingItemStreamItemReader qui n’est pas thread-safe. L’utilisation d’un wrapper synchronized aurait pu être envisagée si la classe fille de JdbcCursorItemReader développée pour les besoins du batch ne s’appuyait pas elle-même sur un RowMapper avec état reposant sur l’ordre de lecture des éléments.
Les Parallel Steps ont été mises en œuvre dès le début du batch pour traiter en parallèle des données de types différents (ex : Musique et Film). De par leurs jointures, les requêtes SQL de chacun différaient. Avant optimisation, 9 steps étaient déjà exécutés en parallèle par ce biais.
Quatrième et dernière technique, celle du Partitioning a Step est la piste que nous avons étudiée pour diminuer le temps d’exécuter des 3 steps les plus longs. Elle consiste à partitionner les données selon un critère pertinemment choisi (ex : identifiant, année, catégorie), le but étant d’obtenir des partitions de taille équivalente et donc de même temps de traitement.
Bien qu’il ne fut pas parfaitement linéairement réparti, le discriminant retenu pour le batch a été l’identifiant fonctionnel des données à indexer. Les données ont été découpées en 3 partitions. Comme attendu, bien que le volume de données soit divisé par trois, le temps de mise en place du curseur Oracle ne diminua pas. Par contre, le temps de traitements fut divisé par 3, faisant ainsi passer le temps d’exécution du batch de 3h à 2h.
Malgré une augmentation du nombre de requêtes exécutées simultanément, la base Oracle n’a pas montré de faiblesse. Une surcharge aurait en effet pu ternir ce résultat.
Exemple de mise en œuvre
Après ce long discours, rien de tel qu’un peu d’exercice. Pour les besoins de ce billet, et afin de capitaliser sur l’expérience acquise sur la configuration Spring Batch, j’ai mis à jour le projet spring-batch-toolkit hébergé sur GitHub. Le fichier blog-parallelisation.zip contient l’ensemble du code source mavenisé.
Je suis parti d’un cas d’exemple des plus simples : un batch chargé de lire en base de données des chefs-d’œuvre puis de les afficher sur la console.
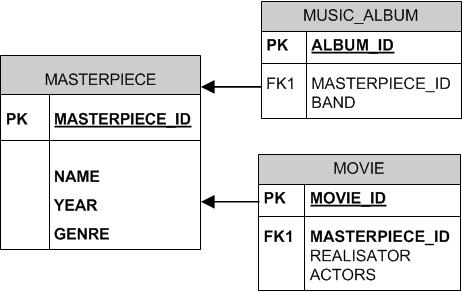
En base, il existe 2 types de chefs-d’œuvre : les films et les albums de musique. Comme le montre le diagramme du modèle physique de données ci-contre, chaque type de chef-d’oeuvre dispose de sa propre table : respectivement MOVIE et MUSIC_ALBUM. Les données communes sont normalisées dans la table MAESTERPIECE.
En ce qui concerne le design du batch, le job peut être décomposé en 2 steps exécutés en parallèle, l’un chargé de traiter les albums de musique, l’autre les films. Une fois les 2 steps terminés, un dernier step affiche le nombre total de chefs-d’œuvre traités.
Avec une volumétrie de film supérieure à celle des albums, le step des films est décomposé en 2 partitions exécutées en parallèle.
Le besoin est simple. Partons d’une démarche TDD et commençons par l’écriture d’un test d’intégration.
Dans un premier temps, attaquons-nous aux données de test, sans doute ce qu’il y’a de plus fastidieux. Exécuté au moment de la création de la base de données embarquée, le script SQL TestParallelAndPartitioning.sql contient les ordres DDL du schéma ci-dessous ainsi que des requêtes INSERT permettant de l’alimenter.
Voici un exemple de données de tests :
Insert <strong>into</strong> MASTERPIECE (MASTERPIECE_ID, NAME, YEAR, GENRE) <strong>values</strong> (2, 'Star Wars: Episode IV - A New Hope!', 1977, 'Movie');
Insert <strong>into</strong> MOVIE (MOVIE_ID, MASTERPIECE_ID, REALISATOR, ACTORS) <strong>values</strong> (1, 2, 'George Lucas', 'Mark Hamill, Harrison Ford, Carrie Fisher');
…
Insert <strong>into</strong> MASTERPIECE (MASTERPIECE_ID, NAME, YEAR, GENRE) <strong>values</strong> (4, 'The Wall', 1979, 'Music');
Insert <strong>into</strong> MUSIC_ALBUM (ALBUM_ID, MASTERPIECE_ID, BAND) <strong>values</strong> (3, 4, 'Pink Floyd');
Au total, 11 albums et 8 films sont référencés.
La classe de tests TestParallelAndPartitioning repose sur Spring Test, Spring Batch Test et JUnit.
Comme le montre l’extrait de code suivant, la classe JobLauncherTestUtils issue de Spring Batch Test permet d’exécuter notre unique job sans avoir à lui passer de paramètres ainsi que d’attendre la fin de son traitement.
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration
public class TestParallelAndPartitioning extends AbstractSpringBatchTest {
@Autowired
private JobLauncherTestUtils testUtils;
@Test
public void launchJob() throws Exception {
// Launch the parallelAndPartitioningJob
JobExecution execution = testUtils.launchJob();
// Batch Status
assertEquals(ExitStatus.COMPLETED, execution.getExitStatus());
// Movies
assertEquals("8 movies", 8, getStepExecution(execution, "stepLogMovie").getWriteCount());
// Music Albums
StepExecution stepExecutionMusic = getStepExecution(execution, "stepLogMusicAlbum");
assertEquals("11 music albums", 11, stepExecutionMusic.getWriteCount());
Object gridSize = ExecutionContextTestUtils.getValueFromStep(stepExecutionMusic,
"SimpleStepExecutionSplitter.GRID_SIZE");
assertEquals("stepLogMusicAlbum divided into 2 partitions", 2L, gridSize);
StepExecution stepExecPart0 = getStepExecution(execution,
"stepLogMusicAlbumPartition:partition0");
assertEquals("First partition processed 6 music albums", 6, stepExecPart0.getWriteCount());
StepExecution stepExecPart1 = getStepExecution(execution,
"stepLogMusicAlbumPartition:partition1");
assertEquals("Second partition processed 5 music albums", 5, stepExecPart1.getWriteCount());
}
L’exécution du job est suivie d’assertions :
- Le job s’est terminé avec succès
- Le step des films
stepLogMoviea traité les 8 films attendus - Le step des albums de musiques
stepLogMusicAlbuma traité les 11 films attendus - Et en y regardant de plus près, le step des albums a été décomposé en deux « sous-steps »,
stepLogMusicAlbumPartition:partition0etstepLogMusicAlbumPartition:partition1qui correspondent, comme leur nom l’indique, à chacune des 2 partitions. Les 11 films ont été séparés en 2 lots de capacités avoisinantes, à savoir de 6 et 5 films. Avec 3 partitions, on aurait pu s’attendre à un découpage de 4-4-3.
La configuration du batch commence par la déclaration de beans d’infrastructure Spring relativement génériques pour des tests :
- Une base de données en mémoire H2 initialisée avec le schéma des 6 tables de Spring Batch
- Le gestionnaire de transactions utilisé par Spring Batch pour gérer ses chunk
- Le
JobRespositorydans lequel seront persistés l’historique et le contexte d’exécution des batchs - Les beans
SimpleJobLauncheretJobLauncherTestUtilspermettant d’exécuter le job testé
Ces beans sont déclarés dans le fichier AbstractSpringBatchTest-context.xml :
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xmlns:p="http://www.springframework.org/schema/p" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:c="http://www.springframework.org/schema/c"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch-2.2.xsd
http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc-3.2.xsd
">
<!-- Create an in-memory Spring Batch database from the schema included into the spring-batch-core module -->
<jdbc:embedded-database id="dataSource" type="H2">
<jdbc:script location="classpath:org/springframework/batch/core/schema-drop-h2.sql" />
<jdbc:script location="classpath:org/springframework/batch/core/schema-h2.sql" />
</jdbc:embedded-database>
<!-- Datasource transaction manager used for the Spring Batch Repository and batch processing -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"
p:dataSource-ref="dataSource" />
<!-- Helps with testing (autowired, injected in the test instance) -->
<bean class="org.springframework.batch.test.JobLauncherTestUtils" lazy-init="true" />
<!-- Starts a job execution -->
<bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>
<!-- In-memory database repository -->
<batch:job-repository id="jobRepository" />
</beans>
La majeure partie de la configuration Spring est définie dans le fichier TestParallelAndPartitioning-context.xml d’où sont tirés les extraits suivants.
En plus du schéma nécessaire par le JobRepository persistant de Spring Batch, les 3 tables de notre exemple sont créées puis alimentées avec notre jeu de données comportant 19 chefs-d’œuvre :
<!-- Initialize database with 8 movies and 11 music albums -->
<jdbc:initialize-database>
<jdbc:script location="classpath:com/javaetmoi/core/batch/test/TestParallelAndPartitioning.sql" />
</jdbc:initialize-database>
Un pool de threads sera utilisé pour paralléliser le job . Ce pool est dimensionné à 4 threads : un thread pour chacun des 2 parallel steps + un thread pour chacun des 2 « sous-steps » correspondants aux 2 partitions.
<!-- Thread pools : 1 thread for stepLogMovie and 3 threads for stepLogMusicAlbum -->
<task:executor id="batchTaskExecutor" pool-size="4" />
Vient ensuite la déclaration du job Spring Batch. L’utilisation des balises split et flow permet de mettre en œuvre les Parallel Steps. Couplée avec l’attribut task-executor, l’enchainement des Steps référencés par les flows n’est alors plus linéaire.
Les 2 flows flowMovie et flowMusicAlbum sont exécutés en parallèle. Une fois ces 2 flows terminés, le step stepEnd terminera le job.
<!-- Job combining both parallel steps and an local partitions -->
<batch:job id="parallelAndPartitioningJob">
<batch:split id="splitIndexDelta" task-executor="batchTaskExecutor" next="stepEnd">
<!-- 2 parall steps. The first one will be partitioned -->
<batch:flow parent="flowMusicAlbum" />
<batch:flow parent="flowMovie" />
</batch:split>
<!-- The stepEnd will be executed after the 2 flows flowMusicAlbum and flowMovie -->
<batch:step id="stepEnd">
<batch:tasklet>
<bean class="com.javaetmoi.core.batch.test.EndTasklet" />
</batch:tasklet>
</batch:step>
</batch:job>
Composé d’un seul step (sans partition), la déclaration du flow flowMusicAlbum chargée de logger les films est la plus simple. De type chunk, le step a un reader utilisant un curseur JDBC pour itérer sur la liste des films. La classe BeanPropertyRowMapper permet d’effectuer le mapping entre les colonnes du ResultSet de la requête SQL et le bean java Movie ; il se base sur le nom des colonnes et le nom des propriétés du bean.
Le writer affiche les propriétés du bean Movie à l’aide de la méthode ToStringBuilder.reflectionToString() d’Apache Commons Lang.
L’attribut commit-interval du chunk est fixé volontairement à 2. Ainsi, le writer est appelé tous les 2 films. Cela permet de voir plus facilement l’enchevêtrement des différents threads.
<!-- The movie flow is composed of a single step that reads all movies then log them -->
<batch:flow id="flowMovie">
<batch:step id="stepLogMovie">
<batch:tasklet>
<batch:chunk writer="anyObjectWriter" commit-interval="2">
<batch:reader>
<bean class="org.springframework.batch.item.database.JdbcCursorItemReader" p:dataSource-ref="dataSource">
<property name="rowMapper">
<bean class="org.springframework.jdbc.core.BeanPropertyRowMapper" c:mappedClass="com.javaetmoi.core.batch.test.Movie" />
</property>
<property name="sql">
<value><![CDATA[
select a.masterpiece_id as id, name, year, realisator, actors
from masterpiece a
inner join movie b on a.masterpiece_id=b.masterpiece_id
where genre='Movie'
]]></value>
</property>
</bean>
</batch:reader>
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:flow>
Le flow chargé de traiter les films est lui aussi composé d’un seul step : stepLogMusicAlbum. Ce dernier est partitionné en 2 (propriété grid-size="2" du handler). Le même pool de threads est utilisé pour traiter les 2 partitions. Le bean chargé de partitionner les données est référencé : partitionerMusicAlbum. Le traitement des « sous-steps » partitionnés est confié au bean stepLogMusicAlbumPartition.
<!-- The music flow is composed of a single step which is partitioned -->
<batch:flow id="flowMusicAlbum">
<batch:step id="stepLogMusicAlbum">
<!-- Executes partition steps locally in separate threads of execution -->
<batch:partition step="stepLogMusicAlbumPartition" partitioner="partitionerMusicAlbum">
<batch:handler grid-size="2" task-executor="batchTaskExecutor" />
</batch:partition>
</batch:step>
</batch:flow>
Le bean partitionerMusicAlbum repose sur la classe ColumnRangePartitioner reprise des samples Spring Batch La clé de partition doit lui être précisé sous forme du couple nom de table / nom de colonne.
Techniquement, cette classe utilise ces données pour récupérer les valeurs minimales et maximales de la clé. Pour se faire, 2 requêtes SQL sont exécutées. A partir, du min et du max, connaissant le nombre de partitions à créer (grid-size), elle calcule des intervalles de données de grandeur équivalente. Afin que les partitions soient de taille équivalente en termes de données, les valeurs des clés doivent être uniformément distribuées. C’est par exemple le cas avec un identifiant technique généré par une séquence base de données et pour lesquelles aucune donnée n’est supprimée (pas de trou). Les clés minValue et maxValue de chaque intervalle sont mises à disposition dans le contexte d’exécution de chaque « sous-step ».
<!-- The partitioner finds the minimum and maximum primary keys in the music album table to obtain a count of rows and
then calculates the number of rows in the partition -->
<bean id="partitionerMusicAlbum" class="com.javaetmoi.core.batch.partition.ColumnRangePartitioner">
<property name="dataSource" ref="dataSource" />
<property name="table" value="music_album" />
<property name="column" value="album_id" />
</bean>
De la même manière que son cousin stepLogMovie, le bean stepLogMusicAlbumPartition est composé d’un chunk tasklet. Celui-ci référence 2 beans définis dans la suite du fichier de configuration : readerMusicAlbum et anyObjectWriter, ce dernier étant déjà utilisé par le bean stepLogMovie.
<!-- Read music albums from database then write them into logs -->
<batch:step id="stepLogMusicAlbumPartition">
<batch:tasklet>
<batch:chunk reader="readerMusicAlbum" writer="anyObjectWriter" commit-interval="2" />
</batch:tasklet>
</batch:step>
Par rapport à celui en charge de la lecture des films, le bean readerMusicAlbum se démarque en 2 points :
- La requête SQL filtre non seulement les chefs-d’œuvre par leur genre (
where genre='Music'), mais également sur une plage d’identifiants (and b.album_id >= ? and b.album_id <= ?) relatifs à la clé de partitionnement. Cette requête est donc dynamique. Basé sur unPreparedStatementJDBC, elle est exécutée autant de fois qu’il y’a de partitions à traiter.
Les 2 paramètres de la requête (symbolisés par un ?) sont évalués dynamiquement à partir du contexte d’exécution du step. Une Spring Expression Language (SPeL) est utilisée dans la définition du bean anonyme basé sur la classe ListPreparedStatementSetter. Ceci est permis grâce à la portée du bean reader qui est de type step (scope=“step”).
<!-- JdbcCursorItemReader in charge of selecting music albums by id range -->
<bean id="readerMusicAlbum" class="org.springframework.batch.item.database.JdbcCursorItemReader" scope="step"
p:dataSource-ref="dataSource">
<property name="rowMapper">
<bean class="org.springframework.jdbc.core.BeanPropertyRowMapper" c:mappedClass="com.javaetmoi.core.batch.test.MusicAlbum" />
</property>
<property name="sql">
<value><![CDATA[
select a.masterpiece_id as id, name, year, band
from masterpiece a
inner join music_album b on a.masterpiece_id=b.masterpiece_id
where genre='Music'
and b.album_id >= ? and b.album_id <= ?
]]></value>
</property>
<property name="preparedStatementSetter">
<bean class="org.springframework.batch.core.resource.ListPreparedStatementSetter">
<property name="parameters">
<list>
<!-- SPeL parameters order is important because it referes to "where album_id >= ? and album_id <= ?" -->
<value>#{stepExecutionContext[minValue]}</value>
<value>#{stepExecutionContext[maxValue]}</value>
</list>
</property>
</bean>
</property>
</bean>
Après épuration des logs et ajout d’un Thread.sleep(50) dans la classe ConsoleItemWriter dans le but, voici le résultat de l’exécution du batch :
Job: [FlowJob: [name=parallelAndPartitioningJob]] launched with the following parameters: [{timestamp=1354297881856}]
Executing step: [stepLogMusicAlbum]
Executing step: [stepLogMovie]
Movie[realisator=George Lucas,actors=Mark Hamill, Harrison Ford, Carrie Fisher,id=2,name=Star Wars: Episode IV - A New Hope!,year=1977]
Movie[realisator=Richard Marquand,actors=Mark Hamill, Harrison Ford, Carrie Fisher,id=6,name=Star Wars : Episode VI - Return of the Jedi,year=1983]
Movie[realisator=Paul Verhoeven,actors=Arnold Schwarzenegger, Sharon Stone,id=7,name=Total Recal,year=1990]
Movie[realisator=James Cameron,actors=Arnold Schwarzenegger,id=11,name=Terminator 2 : Judgement Day,year=1991]
MusicAlbum[band=The Beatles,id=1,name=Help!,year=1965]
MusicAlbum[band=The Police,id=3,name=Outlandos d'Amour!,year=1978]
MusicAlbum[band=Metallica,id=10,name=Black Album,year=1991]
MusicAlbum[band=Radiohead,id=13,name=OK Computer,year=1997]
Movie[realisator=Quentin Tarantino,actors=John Travolta, Samuel L. Jackson, Uma Thurman,id=12,name=Pulp Fiction,year=1994]
Movie[realisator=Peter Jackson,actors=Elijah Wood, Sean Astin,id=15,name=The Lord of the Rings: The Return of the King,year=2003]
MusicAlbum[band=Pink Floyd,id=4,name=The Wall,year=1979]
MusicAlbum[band=U2,id=5,name=War,year=1983]
MusicAlbum[band=Muse,id=14,name=Showbiz,year=1999]
MusicAlbum[band=Muse,id=16,name=The Resistance,year=2009]
Movie[realisator=Christopher Nolan,actors=Leonardo DiCaprio, Marion Cotillard,id=17,name=Inception,year=2010]
Movie[realisator=Christopher Nolan,actors=Christian Bale, Gary Oldman,id=18,name=The Dark Knight Rises,year=2012]
MusicAlbum[band=U2,id=8,name=Achtung Baby,year=1991]
MusicAlbum[band=Nirvana,id=9,name=Nevermind,year=1991]
MusicAlbum[band=Saez,id=19,name=Messina,year=2012]
Executing step: [stepEnd]
19 masterpiece(s) have been processed
Job: [FlowJob: [name=parallelAndPartitioningJob]] completed with the following parameters: [{timestamp=1354297881856}] and the following status: [COMPLETED]
Ces traces confirment que le traitement des chefs-d’œuvre est équitablement réparti dans le temps et entre les différents threads, avec une alternance de films et d’albums de musique, et des albums des 2 partitions traités en parallèle.
Conclusion
Pour un effort minime, à peine quelques heures de développement, la durée d’exécution du batch a baissé de 33%, avec un débit avoisinant les 5 000 documents par secondes indexés dans ElasticSearch. Pourquoi donc s’en priver ?
La documentation Spring Batch doit être attentivement suivie pour ne pas tomber dans certains pièges liés à la parallélisassion. La documentation officielle, le livre Spring Batch in Action et maintenant ce billet devraient être des sources suffisantes pour comprendre et mettre en œuvre aux moins 2 des techniques proposées nativement par Spring Batch : Parallel Steps et Partitioning a Step.